
{kind=link}
Table of Contents
引言
在构建和优化AI系统时,有效的评估机制是成功的关键。本文总结了关于AI评估系统的五个重要经验教训,这些经验来自于实际项目中的实践和反思。
经验一:什么是有效的评估
核心要点
评估系统必须能够快速证明其对组织或AI系统的价值,主要体现在以下几个方面:
1. 新模型快速评估能力
- 24小时决策能力:当新模型发布后,系统必须能够在24小时内判断是否能够整合到现有系统中
- 明确评估指标:需要建立清晰的评估指标和维度,针对具体的Agent或AI项目制定标准
- 快速切换机制:基于评估结果,能够快速决定是否进行模型切换
2. 用户反馈整合机制
- 负面反馈处理:将线上用户的负面反馈及时纳入评估体系进行改进
- 持续优化循环:建立持续评估和改善的机制
- 防止过拟合:不是所有数据集的bad case都要加入测试集,需要人工审核
- 专业判断:需要有经验丰富的人员判断哪些问题应该被纳入测试集
3. 主动安全测试
- 恶意用户模拟:主动扮演恶意用户来发现问题,而不是等待真实恶意用户发现问题
- 边缘情况测试:建立更明确的安全测试和其他攻击性测试措施
- 预防性评估:在问题发生前就发现潜在风险
经验二:优秀的评估需要精心设计
关键原则
1. 数据集必须与现实保持一致
- 真实数据优先:标准测试集只是标准环境下的表现,不是真实世界的标准
- 合成数据局限性:合成数据无法完全反映真实情况
- 用户行为数据:只有能够反映真实用户使用数据和体验的数据才能作为有效的测评依据
2. 评分标准是项目的规格说明
- 评分即规格:评分标准实际上是你项目的规格说明,就像产品的PRD一样
- 参考而非照搬:可以借鉴他人的评分标准作为参考,但必须根据现有项目进行修改
- 项目定制化:评分标准必须符合当前项目的具体需求
- 动态调整:评分标准应该随着项目发展而调整
经验三:上下文工程是新的提示工程

核心概念
工具调用的优化
- 清晰的功能说明:让模型清楚理解工具能做什么
- 结构化输出:当模型调用工具时,如果能得到清晰的输出,表现会更好
- 量化简化:将输出变得量化、简单、清晰,效果会更好
输出格式优化
- JSON格式优势:如果返回JSON格式,将其转换为schema模式或mark模式会更清晰
- Token节省:更节省token的方式给模型提供更好的信息
- 上下文工程考量:这是上下文工程中对工具的重要考量因素
经验四:为新模型改变一切做好准备
模型更新策略
- 能力突破识别:当新模型出现时,过去做不到的事情现在可能能做到
- 评估指标更新:关注那些以前做不到但现在能做到的指标
- 模型切换准备:当评估确认新能力没问题时,就可以进行模型切换
- 持续监控:保持对新模型能力的持续监控和评估
经验五:优化整个评估系统,而不仅仅是提示词
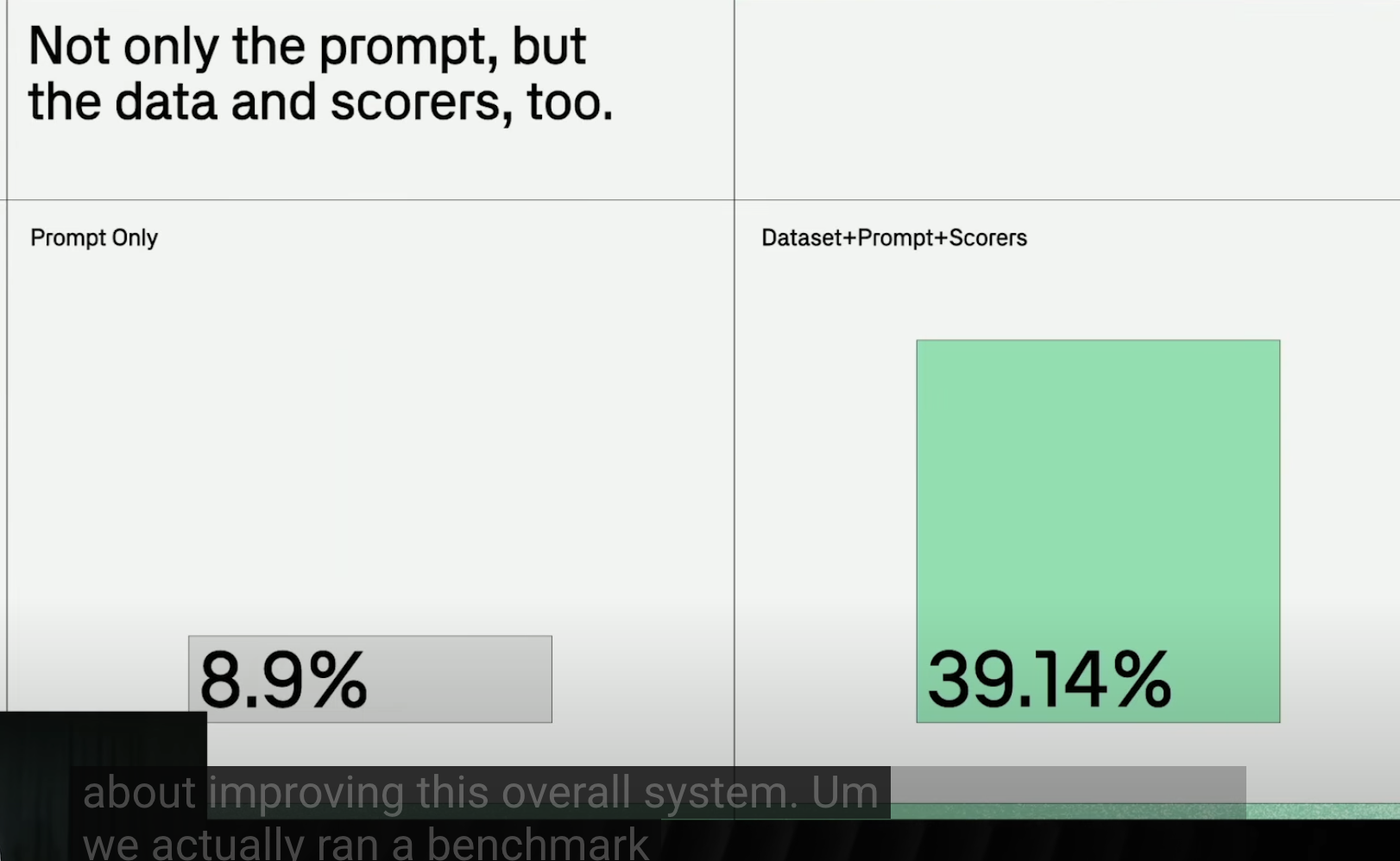
自动化评估循环
注意:这里说的data是测试后的数据集,并不是RAG原始资料的数据集。
核心方法:自动化评估循环(The Automated Evaluation Loop)
这个过程不是人手动一次次问聊天机器人,而是用一个脚本或一个平台(像视频里提到的Brain Trust的”Loop”功能)来自动完成。
循环步骤:
- 初始化:初始Prompt + 测试数据集 + 评分函数
- 运行评估:系统用当前Prompt在测试用例上运行,生成实际输出
- 分析结果:
- 计算总体指标(如准确率)
- 识别错误模式:哪些例子错得最离谱?哪些错误是同一类的?
- 寻找薄弱环节:在哪些类型的输入上,Prompt表现不稳定?
- 生成优化假设:LLM优化器查看失败案例,提出优化方案
- 测试优化假设:自动将新的Prompt在测试集上再次运行,验证优化效果
- 循环迭代:重复步骤2-5,直到评分达到满意水平
具体示例:客户邮件分类系统
原始Prompt (A):
请对以下客户邮件进行分类,直接回复类别名称。类别选项:投诉、咨询、售后、其他。
邮件内容:{email_input}
评分函数:
def score_function(expected_output, actual_output):
return 1 if expected_output == actual_output else 0
优化过程:
第一步:错误案例分析 给优化器LLM发送包含错误案例和上下文的指令:
你是一个AI提示词优化专家。我有一个提示词和一个分类任务,但效果不理想。以下是一些分类错误的案例:
【案例1】
- 输入邮件:"我上个月买的冰箱不制冷了,门封条好像也有问题,这质量太差了,赶紧派人来修!"
- 期望输出:"售后"
- 当前提示词实际输出:"投诉"
【任务】
请分析上述错误,找出当前提示词的潜在问题。然后,请生成一个优化后的新提示词(Prompt B),旨在减少这类错误。
第二步:优化器分析和回应 优化器LLM分析问题并生成优化后的提示词:
请严格按照以下规则对客户邮件进行分类:
1. **投诉**: 邮件主要表达强烈愤怒、不满,并提出批评,核心目的是抱怨而非直接解决问题。
2. **售后**: 邮件主要描述产品/服务遇到的具体问题,并请求维修、退换货或查询问题状态(即使带有不满情绪)。
3. **咨询**: 邮件主要询问产品功能、价格、服务流程等基本信息,目的是获取信息。
4. **其他**: 不属于以上三类的邮件,例如求职、推销、合作伙伴询价等。
请仔细分析邮件内容和主旨,选择最合适的一个类别。**只输出类别名称,不要输出任何其他内容。**
邮件内容:{email_input}
第三步:自动化验证 系统自动将Prompt B应用到全部测试数据,计算新的平均分,检查之前失败的案例是否得到改善。
第四步:持续迭代 如果分数还不够理想,继续收集新的错误案例,进行下一轮优化。
如何有效”告诉”模型
- 精选错误案例:不是给100条数据,而是给10-15个最典型的错误案例
- 提供完整上下文:明确告诉原始Prompt、期望输出、实际输出
- 具体明确指令:不是”请优化”,而是”请分析以下错误并生成解决了这些特定问题的新Prompt”
- 自动化支持:依靠自动化系统做重体力活,让LLM优化器专注于分析和创意工作
总结
这五个经验教训为构建有效的AI评估系统提供了系统性指导:
- 价值导向:评估必须能够快速证明其价值
- 精心设计:评估系统需要与现实保持一致,评分标准要项目定制化
- 上下文优化:上下文工程是提升模型表现的关键
- 适应变化:为新模型的能力突破做好准备
- 系统优化:优化整个评估系统,而不仅仅是单个组件
通过遵循这些原则,可以构建出更加高效、可靠的AI评估系统,为AI项目的成功提供有力保障。
原视频: https://www.youtube.com/watch?v=a4BV0gGmXgA
大家一起来讨论