
Table of Contents
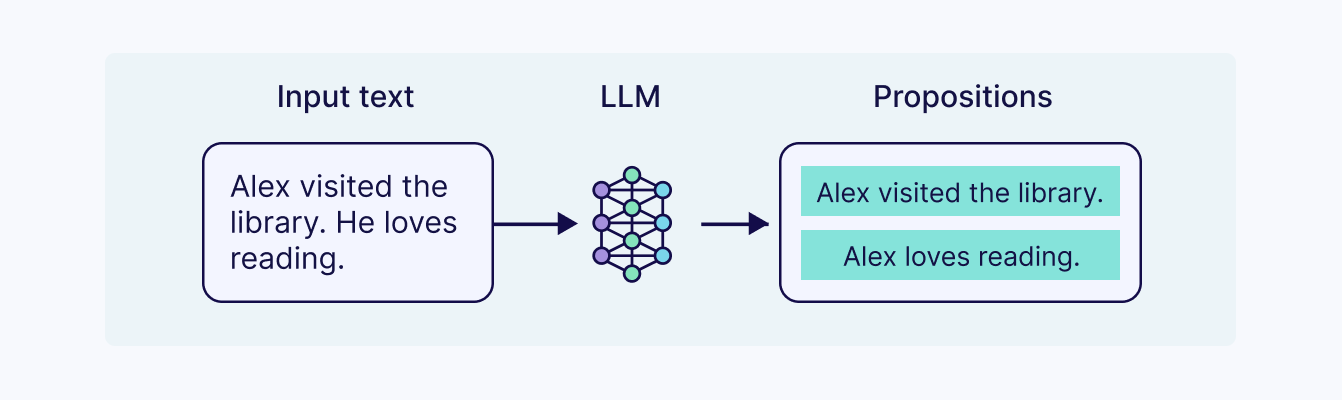
 缺点:
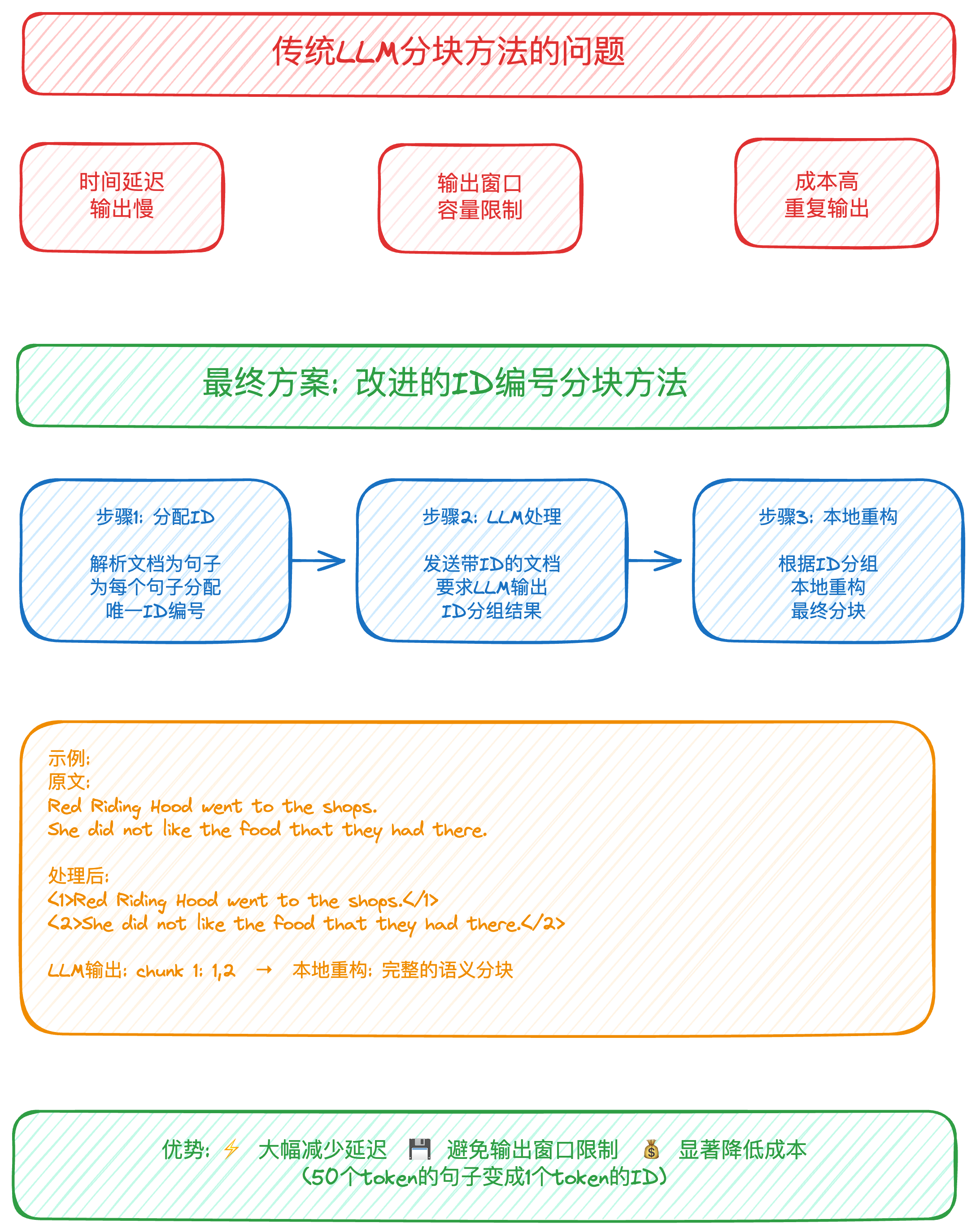
缺点:
- Time/latency -> it takes time for the LLM to output all the chunks.
- Hitting output context window cap -> since you’re essentially re-creating entire documents but in chunks, then you’ll often hit the token capacity of the output window.
- Cost - since your essentially outputting entire documents again, you r costs go up.
可以结合contextual rag : 补充终极RAG方案
注意: 拆分的时候,很多时候不用拆句子, 根据换行符拆分就可以.
reddit: https://www.reddit.com/r/LocalLLaMA/comments/1kmcdyt/llm_better_chunking_method/ chunking-strategies-for-rag: https://weaviate.io/blog/chunking-strategies-for-rag#agentic-chunking
实现的代码
[[相关代码已经放到知识星球了]]


{kind=link}
大家一起来讨论