
https://www.youtube.com/watch?v=OFfwN23hR8U
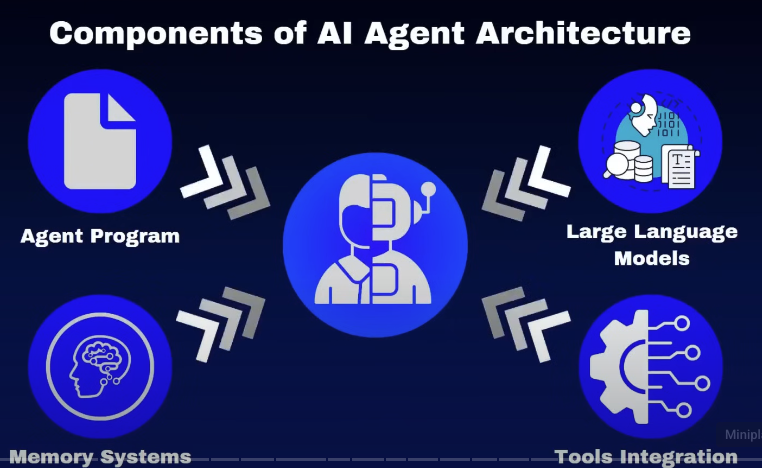
What is an Al Agent?
An Al agent is a program that uses an LLM to reason about how it interacts with its environment and to take varying courses of action to achieve a goal.

AI来干活,你来承担责任

嗯,其实这里边就说就像你写邮件一样。嗯,这个你不太可能让AI把邮件的整个的回复都帮你做好。最合理的方式是这个邮件是否要发出是由已决定的。所以AI的话最合理的方式是帮你把草稿写好,你来审核。然后呢,所以呢就回到这个主题,让AI帮你去省时间,而不是替代你
所以这里边的关键动点是你用的AI,其实他的责任就归属于你是你决定用他的那他发布的任何东西,任何言论都由你承担责任.
agent开始开发之前,它的设计很重要
• Step 1 - Plan the Agent
- What are the core functionalities? • Which LIM do I want to use? • Which APis do I need to set up? • What does a good “vI” look like? Step 2 - Prototype Agent with no/low Code Tools • Goal is to get started fast You can always sun witals bozow code • Use tools like n8n, Flowise, and Voicellow • Build until the agent is working and useful • Don’t focus on the frontend/database yet

小心错误概率的叠加
这个其实就是吴恩达说的的双奇迹问题,所以A2A协议的话还需要再等一等。每一个模型它的节点都是有成功概率的,成功概率加起来的话是一个乘积关系,成功概率就会变低了

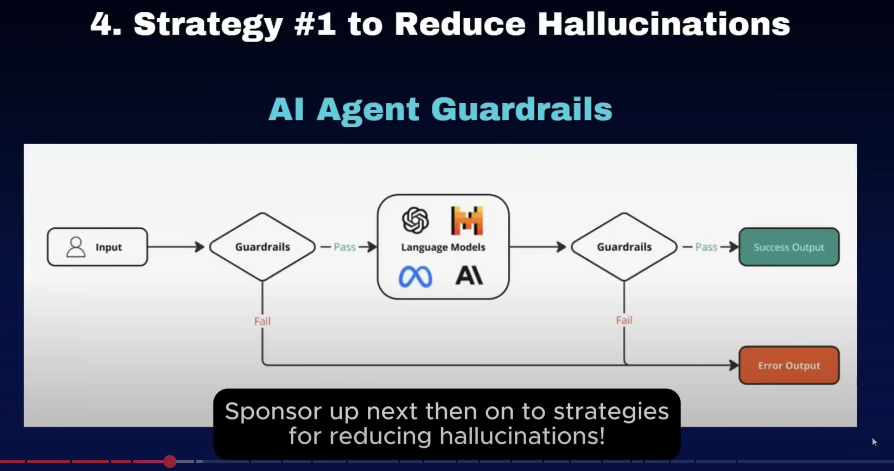
4. 前置和后置验证
这部分也是防止他输入的错误。就比如说第一部分的话。我们在前值的这个保护的验证的是验证用户的数据是否全面了,是否合法。嗯用户提出参数是不是都对。然后最后的验证的是验证我模型输出这些内容是否符合当时用户提出的input的要求。然后如果后边验证的这个是不符合用户提出来的要求,我们就把它进行一个报错。呃,那如果符合用户的要求的话,我们再进行输出. 这里边选择的模型呢都不用太大,因为都是简单的判断任物,要考虑整个流程的延迟. (比如8b左右的模型)
专业化分工这些A站让一个大脑区域指派活,其他的是专门的做相应的事情

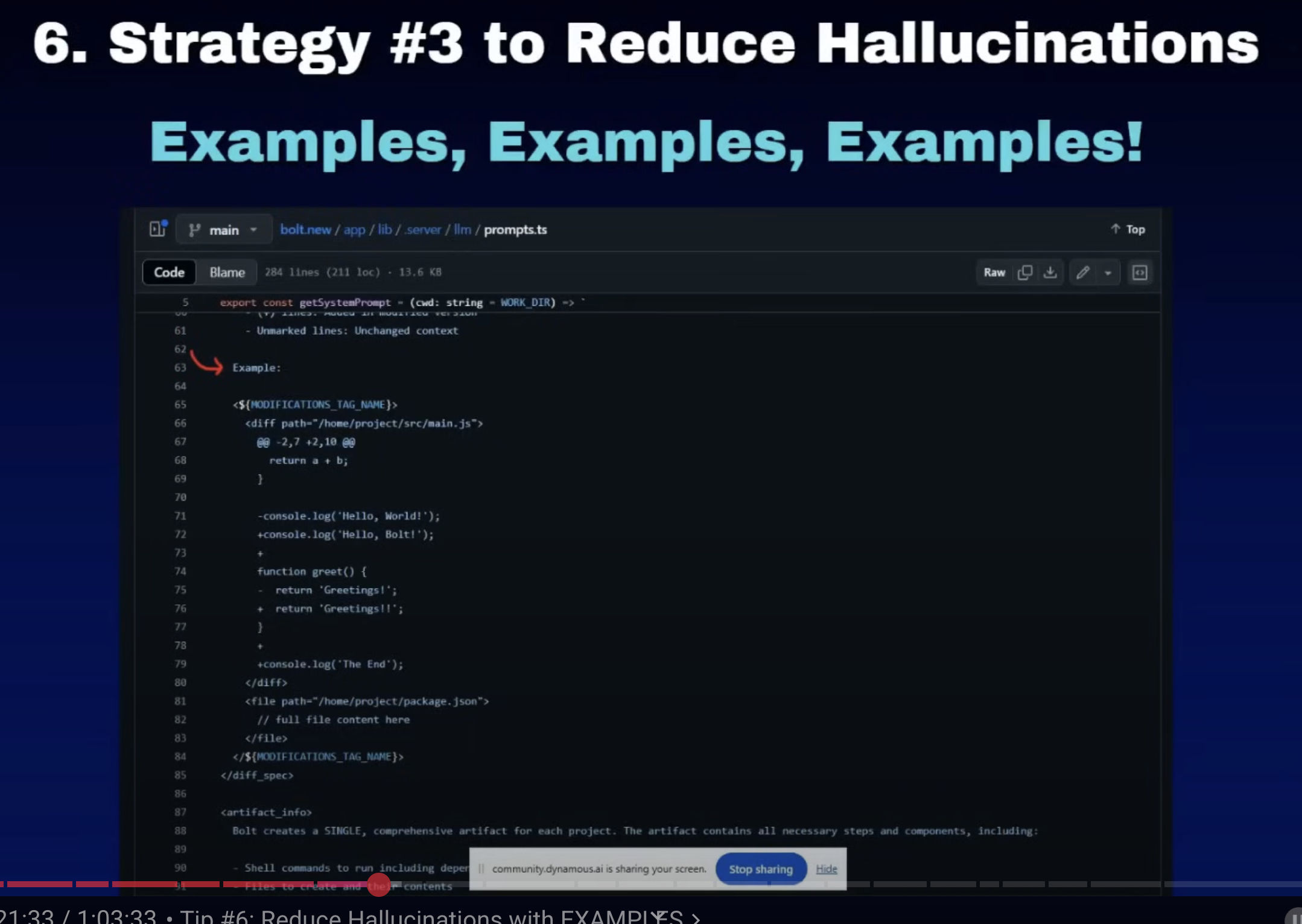
6. 提供样例
7. System Prompt - Avoid Adding Negatives
🎼我感觉这个例子就好像不要像白熊一样

8. avoid contradictions

9. version your prompt
langfuse manage prompt version , this is a good place to manage prompt version.

10 to test it before swapping llm is important

11. Your Favorite LLM isn’t Always the Best!

12. 上下文丢失
- **临时方案
- 每次你发言时,都把那条重要指令复制粘贴到输入框的最前面再发送。
- 雇一个秘书,记住所有重要规矩,每次你发言前,秘书都把最相关的规矩提醒一下。(长期记忆)
- **根本方案
- 换一个更大的LLM(换上下文更长的模型)。
- 让大家说话简洁点,别发长语音(优化应用,减少不必要的token消耗)。比如说必要的rag信息进行检索放到上下文中.

13. 新上下文窗口的重要性
Especially in a conversation within the context of a single session, if it has made mistakes before, it is more likely to make errors again. So the best approach is to reduce the context window size, summarize the information from previous interactions first, and then start a new conversation window. This helps minimize the probability of repeating mistakes made in earlier dialogues.

14. memory is another rag
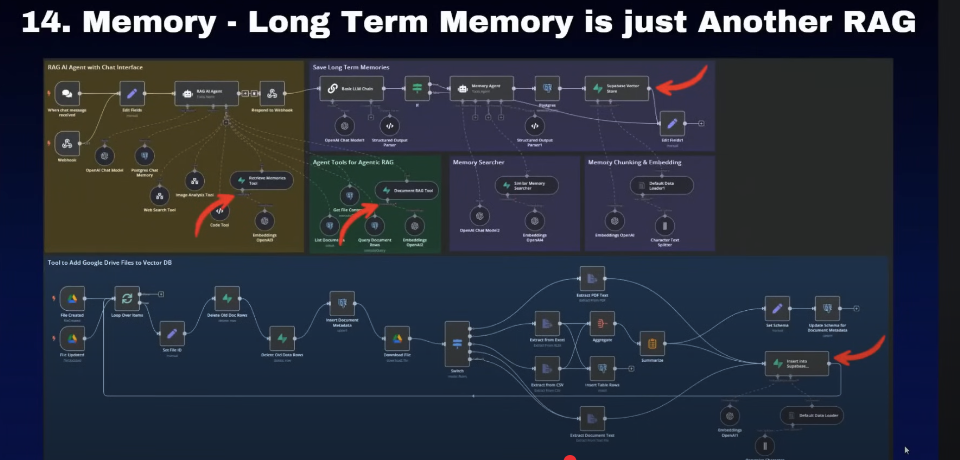
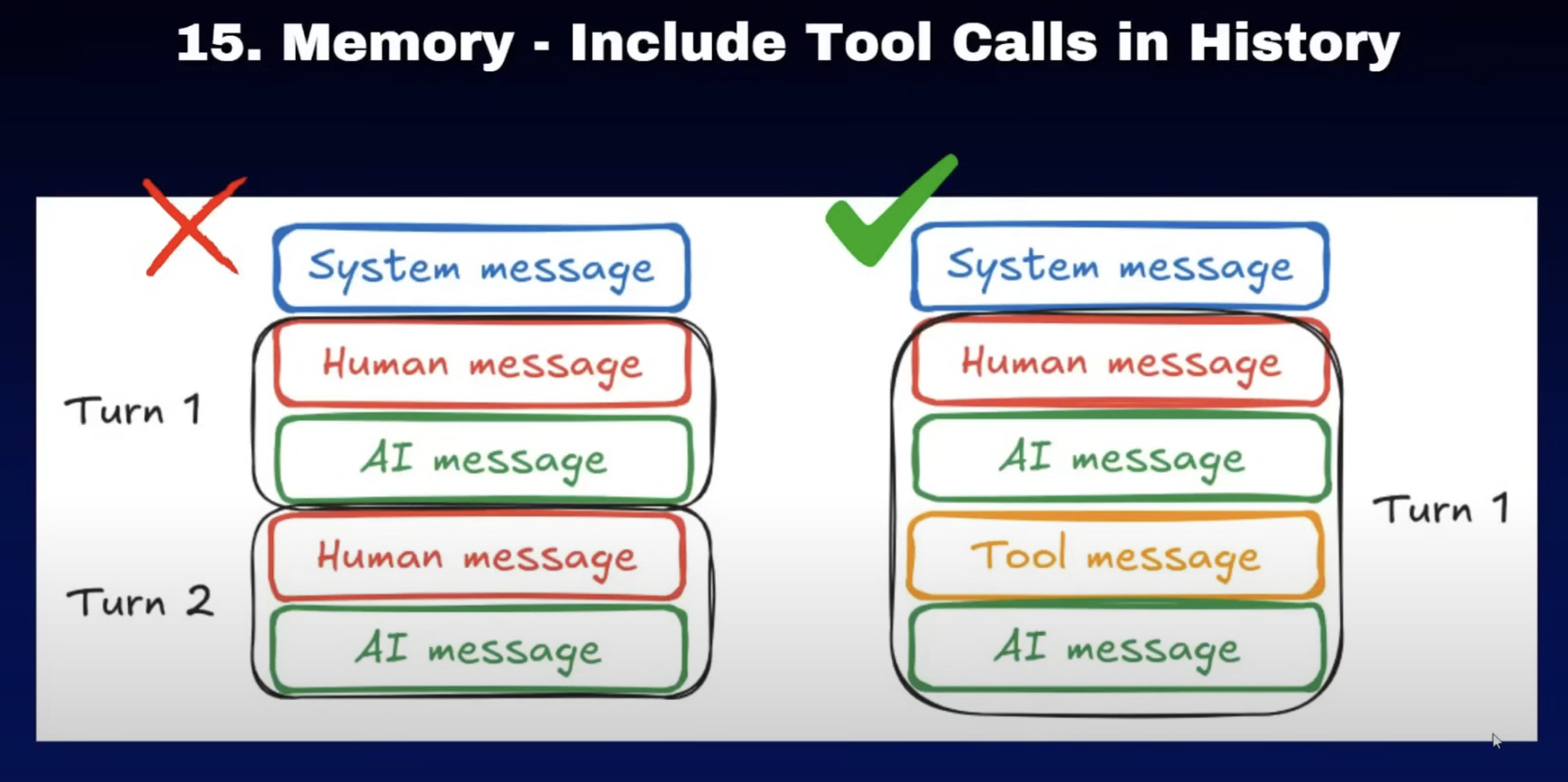
15. memory should inclue tool calls
比如说这里边的例子是,如果我们的工具呢是使用RAG工具进行查询的。如果工具里边的信息呢都在整个历史对话中,那在后边呢我们进行询问的时候,他就会利用历史对话中RAG已经检索的信息。在我们后续对话中继续帮我们做回答
16 tool descriptions
其实这里边这一点建议呢正好和前两天在做anthropic的关于agent中的最佳实践里边的建议其实是一样的。tools description我们不可能把这些直接给到模型以后,他们就直接去帮我们自动进行选择的。很多时候他们是不知道什么时候去用的。所以这时候我们需要去配合我们的system prompt的告诉整个agent的模型,什么时候去使用这些工具,这一点是非常重要的。

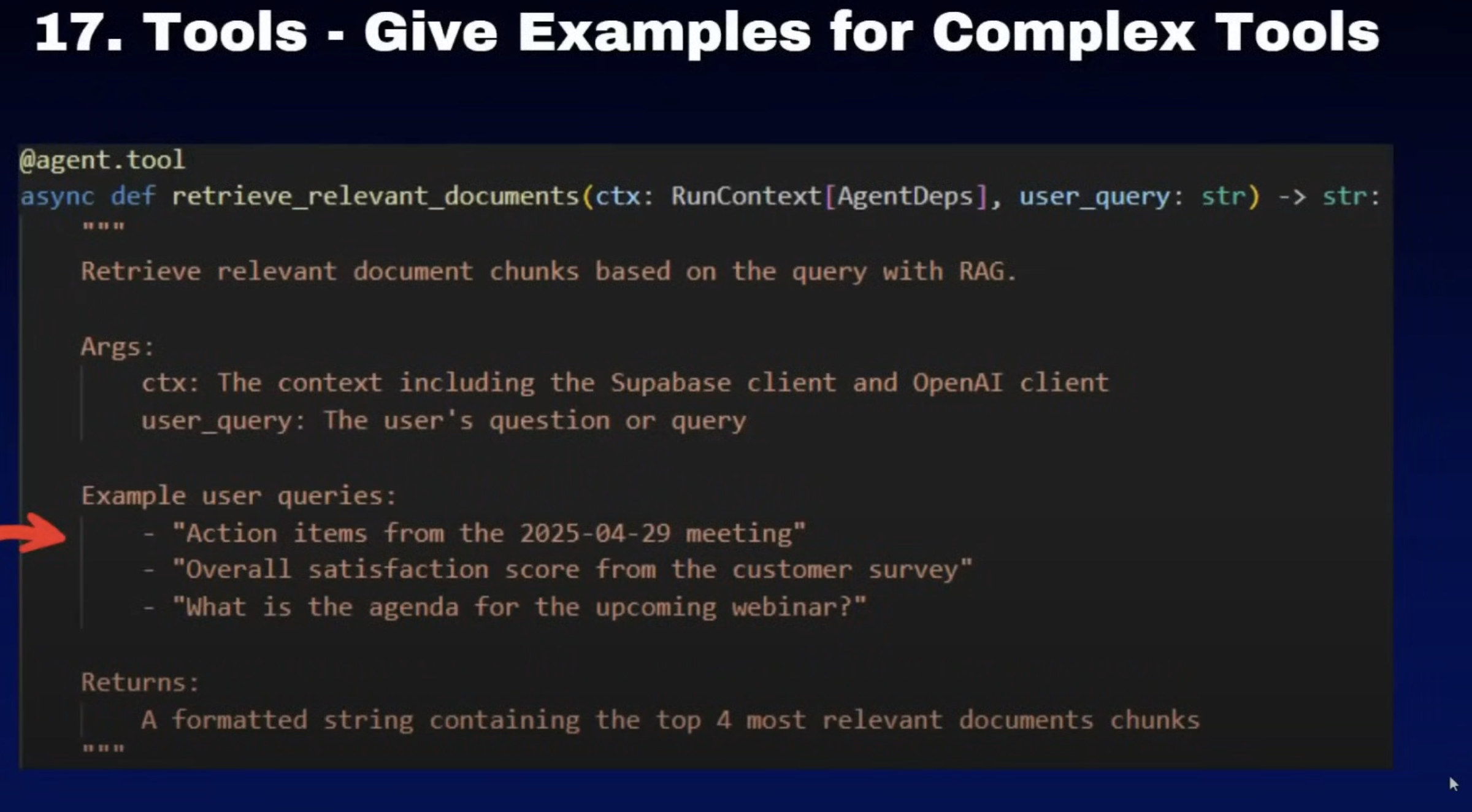
17. tools-give some examples
这里边的一个启发是当我们定义一个工具的时候,这些工具里边的参数呢,我们可以给他一些例子。那这样的话,模型在格式化参数的时候就会格式化我们例子中的样子
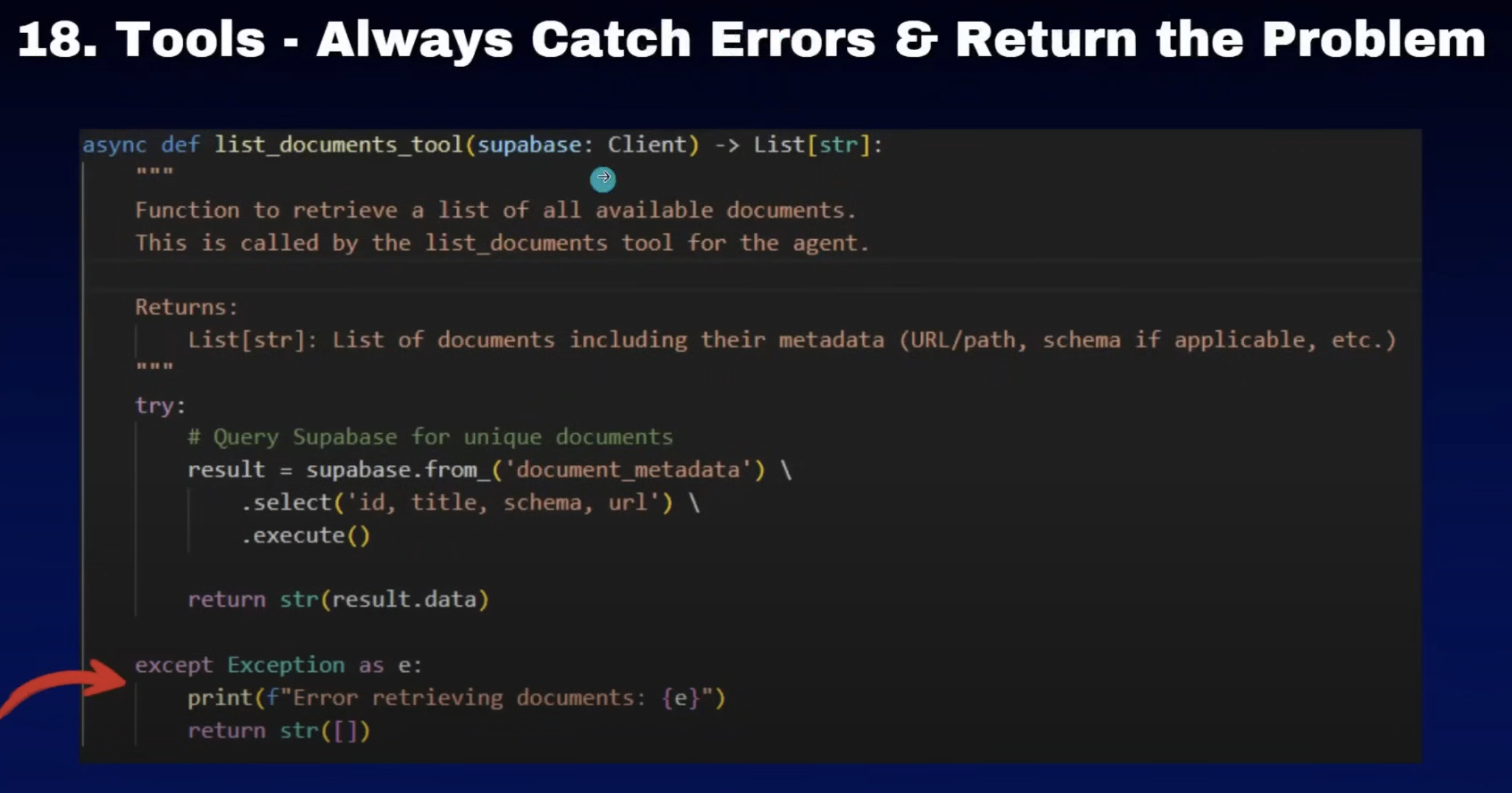
18. catch errors and return the problem
错误的话,一定要cach住,我们可以把这些信息呢记录下来。因为如果你不cach的话,就会让你的整个应用进行崩溃。这个是我们不希望看到的,因为工具的话也很有可能调用的时候是因为语言模型将它的参数翻译错了,这里面重要的一点的话,如果你返回的是一个字符串信息的话,你如果可以给他返回一个关于这里边。调用模型的详细错误给到语言模型。然后语言模型呢看到这个工具调用错误之后呢,它就会进行二次的调用,这样会让。工具和语言模型交互的时候更友好
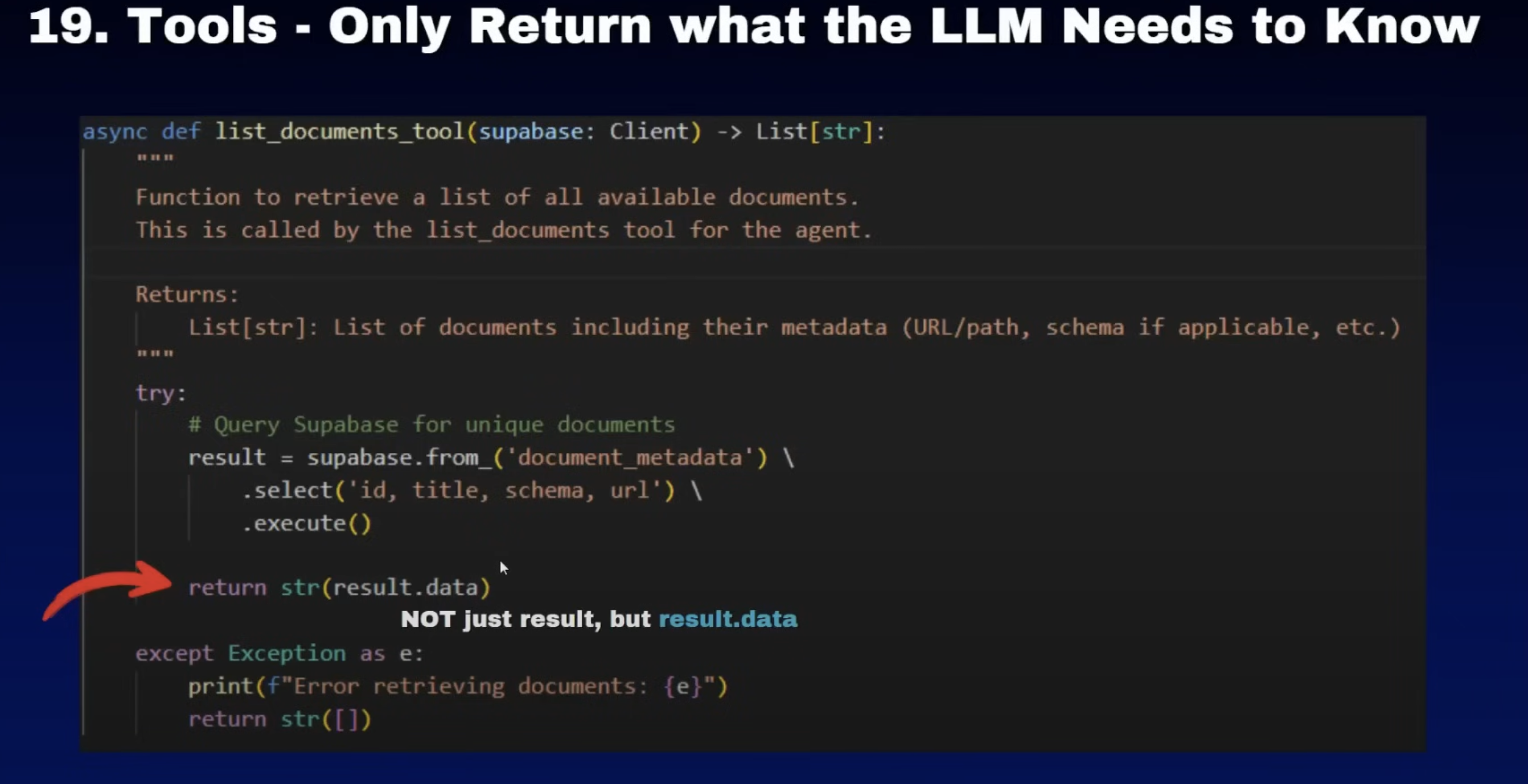
19. tools- return what llm return
其实这里边还有一个问题,就是当你返回一个调用其他API接口的数据的时候,一定要注意这些数据里边的信息,尤其一些源信息是否是你真的需要的。你需要给到语言模型的,其实只是这个工具调用之后返回的关键信息就可以。比如说你调用一个天气的API他告诉你原信息里边有多少个字,然后调用了多少时间,其实这些都不是你工具关心的内容。那这些信息你就不需要返回给原模型,你需要返回的只是天气信息
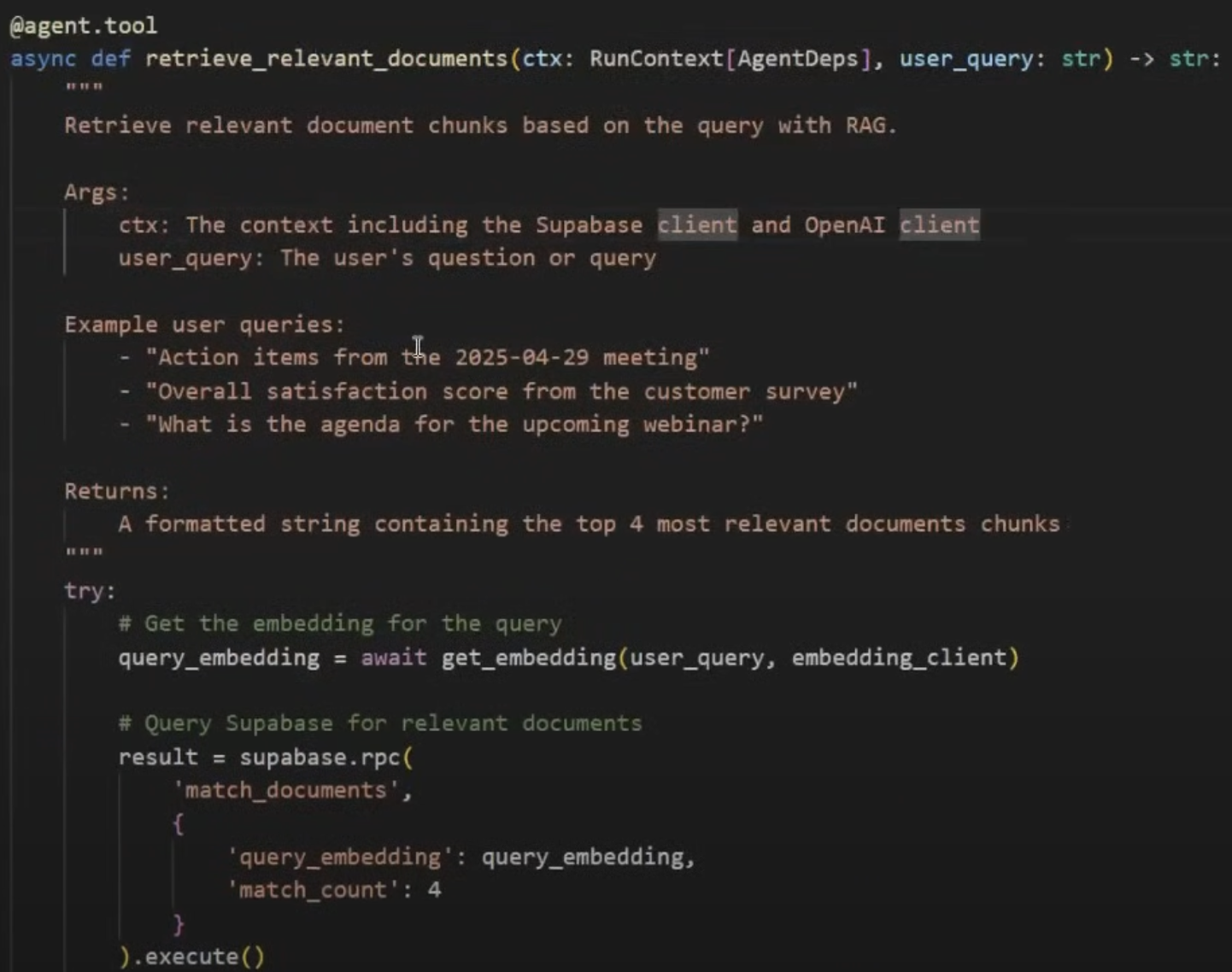
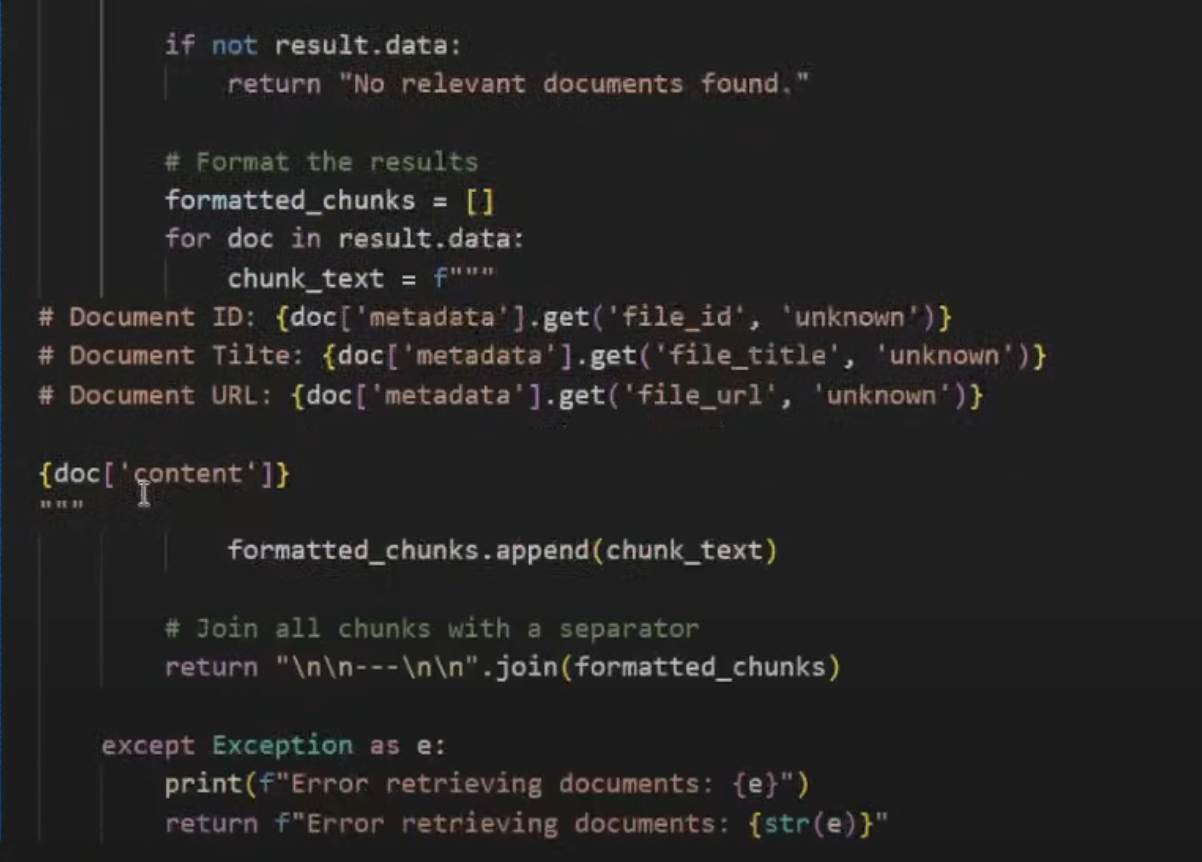
20. tools- good example
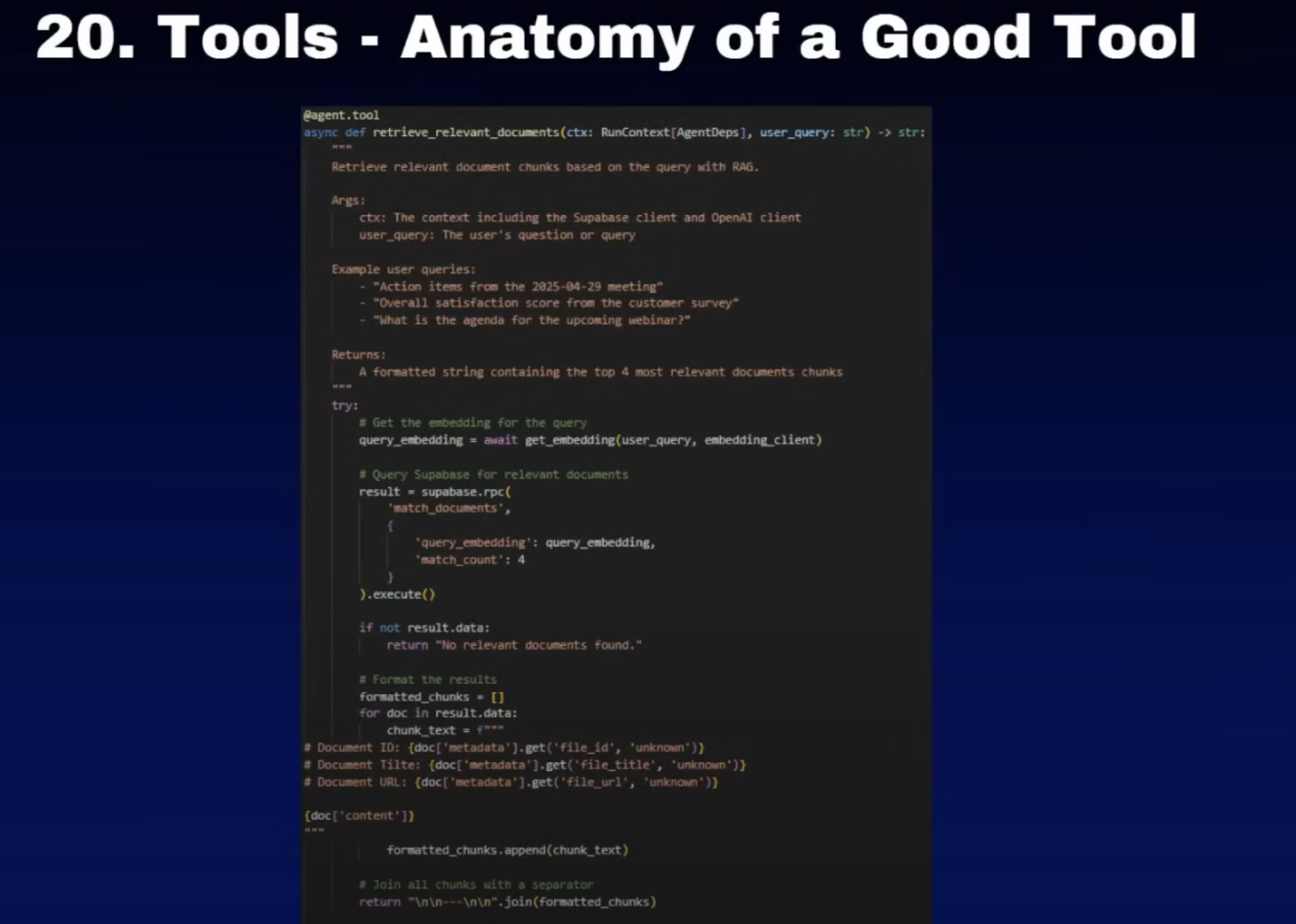
[[解决RAG断章取义]]
这里面一定要注意的话,就是如果我们使用markdown的方式进行工具的格式返回的时候,大模型读取的时候会更容易理解
LLM as judge
好的,这句话阐述了一个非常重要的、用于优化AI系统提示(System Prompt)的高级技巧。我们来分解一下。
核心意思解读
这句话的意思是:
当你设计了一个给AI的角色指令(系统提示)后,如何科学地判断它的好坏并进行优化? 尤其是当你为不同的AI模型(如从GPT-4换到Claude 3)切换提示时,一个强大的方法是使用“LLM即法官”(LLM as a judge)的评估方式。
- “LLM as a judge”: 让另一个AI模型(通常是更强大的模型,如GPT-4)来扮演“裁判”或“质检员”的角色。
- “evaluate your agent’s responses”: 这个“裁判”的任务是评估你的AI助手根据系统提示生成的回答质量。
- “generate requests”: 或者,这个“裁判”甚至可以自动生成大量、多样的测试问题(user requests)来考验你的AI助手。
- “automatically tune the system prompt”: 通过这种自动化的大规模测试和评估,你可以得到数据反馈,从而系统地、高效地调整和优化你的系统提示,而不是靠瞎猜。
- “manual adjustments are often more effective”: 作者也客观指出,有经验的人工调整通常效果更好(因为人有直觉和深层理解)。
- “automated evaluation can provide useful feedback for refinement”: 但自动化评估提供了一个非常有用的、规模化的反馈工具,来辅助人工进行 refinement(精炼、微调)。
举例说明
假设你正在为一个客户服务AI设计一个系统提示。
第一步:初始系统提示
你写了一个初版提示:
“你是一个友好且高效的客户服务代表。请用中文回复用户关于产品‘智能手表X’的咨询。”
第二步:手动测试 你自己问了几个问题,比如“手表防水吗?”,AI回答“是的,我们的智能手表X支持50米防水。” 看起来不错,但你不知道这个提示在成百上千个不同问题上是否都表现良好。
第三步:搭建“LLM即法官”的自动化评估 你设置了一个自动化流程:
- 测试集生成: 你让一个强大的LLM(如GPT-4充当“题目生成器”)自动生成100个用户可能问的、各种各样的问题。
- 例如:“怎么充电?”、“死机了怎么办?”、“和iPhone兼容吗?”、“帮我退货”、“骂你们的产品很烂”……
- 获取回答: 让你的AI助手(使用初版系统提示)逐一回答这100个问题,生成100个回答。
-
法官评审: 你再让另一个强大的LLM(如另一个GPT-4实例充当“法官”)根据一套你定义的标准,来自动评估这100个问答对。
你给“法官”的评判指令(Evaluation Prompt)可以是: `“请评估以下客服回答的质量。总分1-5分,评判标准:
- 专业性(是否准确、可信)
- 友好性(语气是否积极、有同理心)
- 有效性(是否解决了问题或给出了清晰指引) 请最后输出格式为:『评分:X』”
【用户问题】:{插入问题} 【客服回答】:{插入回答} `
- 分析结果: 你收集100个问题的评分,计算平均分,并找出哪些问题得分最低。
第四步:优化提示 通过分析低分回答,你发现了问题:
- 当用户问“怎么退货”时,AI只是泛泛地说“请联系我们”,没有提供具体步骤,因此“有效性”得分低。
- 当用户愤怒地骂产品时,AI的回答依然机械礼貌,缺乏共情,因此“友好性”得分低。
于是你优化系统提示为V2版: `“你是一个友好且高效的客户服务代表。请用中文回复用户关于产品‘智能手表X’的咨询。 重要要求:
- 对于退货等流程性问题,请提供具体步骤:『1. 登录官网;2. 进入订单页…』。
- 如果用户情绪愤怒,请先道歉并表示理解,例如:『非常抱歉给您带来了不好的体验,我完全理解您的 frustration…』,然后再解决问题。” `
第五步:循环迭代 你用同样的100个问题,测试V2版提示,再次让“LLM法官”评分。如果平均分从3.5提升到了4.6,说明你的优化是成功的。你可以不断重复这个过程,直到满意为止。
为什么这很有用?
- 规模(Scale): 人工无法测试上千个案例,但自动化可以。
- 一致性(Consistency): “LLM法官”会用同一套标准评判所有回答,避免人工评判的疲劳和不一致。
- 洞察(Insight): 它能系统地帮你发现你没想到的薄弱环节。
- 跨模型适配(Cross-Model Tuning): 当你把为GPT-4设计的完美提示直接用于Claude 3时,效果可能变差。你可以用Claude 3重新跑一遍这个评估流程,来为它专门优化提示,而不需要从头开始。
总而言之,“LLM as a judge”不是完全取代人工,而是给人配备了一个强大的“数据分析工具”,让提示优化过程从一种“艺术”变得更像一门“科学”。



{kind=link}
大家一起来讨论