
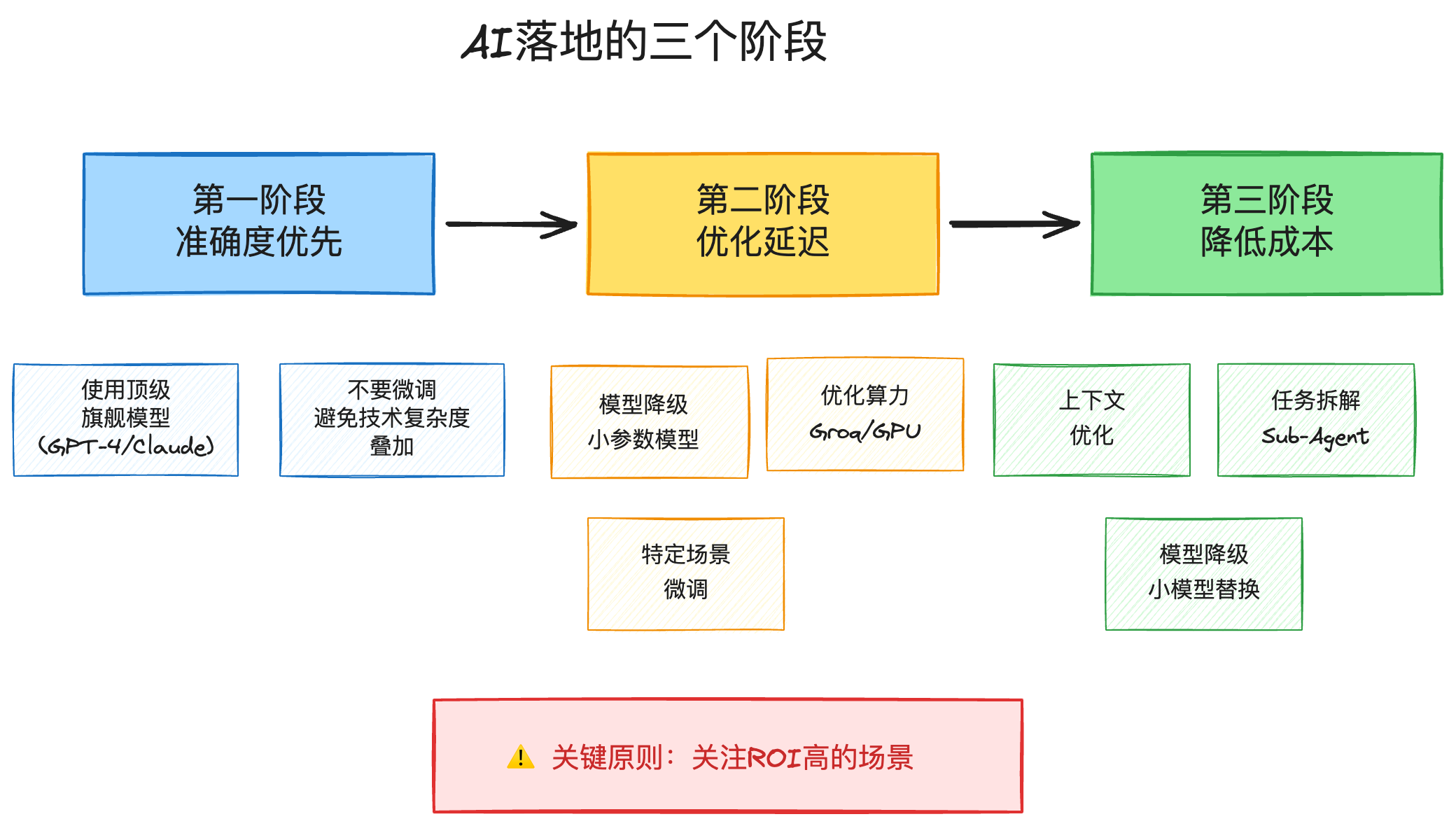
AI项目落地需要遵循三个核心阶段:准确度、延迟和成本。这三个阶段环环相扣,需要按顺序逐步优化。
第一阶段:准确度优先
核心原则
在AI落地的初期阶段,准确度是第一要务。如果模型的准确度无法满足业务需求,优化其他方面就毫无意义。
实施策略
1. 使用顶级旗舰模型
- 选择各大厂商的最强模型(如千问最优版、DeepSeek最优版、GPT-4、Claude最优版等)
- 目的:确保提示词设计本身是有效的
- 避免陷阱:不要用小模型测试,否则无法判断问题出在提示词还是模型能力上
2. 关于微调的建议 在第一阶段不要考虑微调,原因如下:
- 微调增加技术复杂度,会与业务复杂度叠加,导致实现困难
- 微调需要全面评估模型的基础理解能力是否下降,测试成本极高
- 现有通用模型(相当于本科生到研究生水平)已能满足大多数垂直领域需求(电商、法律、客服等)
- 先用最好的模型把场景跑通,建立准确度基线
第二阶段:优化延迟
当准确度问题解决后,进入第二阶段——优化响应延迟,提升用户体验。
优化方案
方案一:模型降级
- 尝试将大模型替换为参数更小的模型
- 小模型推理速度更快,可降低延迟
方案二:选择更优算力厂商
- 为追求更好的用户体验,可以选择响应速度更快的服务商 (比如groq)
- 适当增加预算(GPU),换取更低的延迟
方案三:特定场景的微调 以知识库路由为例,这是微调的理想场景:
- 第一步:使用大模型完成路由任务,积累一段时间的运行数据
- 第二步:收集真实用户反馈和测试数据,确保准确性
- 第三步:将这些高质量数据作为训练集,微调一个小模型
- 结果:既保证了准确度,又降低了延迟
第三阶段:降低成本
只有当准确度和延迟都达标后,才进入第三阶段——成本优化。
优化策略
1. 结合商业模式考虑成本 根据业务的盈利能力和用户付费意愿,制定合理的成本目标。
2. 引入技术优化手段 参考成熟产品的实践(如 Cursor):
- 上下文优化:更精准的上下文管理,减少token消耗
- 任务拆解:使用 to-do list 等方式拆解复杂任务
- 子代理模式:其他IDE也有引入 sub-agent 架构
- 模型降级:在保证质量的前提下,将部分场景替换为更小的模型
3. 持续迭代 利用各种技术手段,在不影响用户体验的前提下,逐步降低完成业务场景的成本。
总结
AI落地三阶段的核心逻辑:
- 准确度阶段:不惜成本,用最好的模型验证场景可行性
- 延迟阶段:在保证准确度的前提下,优化响应速度
- 成本阶段:通过技术手段,在不损失质量的情况下降低成本
关于我
- 如果你是一家科技公司,特别是致力于AI应用技术研究,请一定要重视AI工程化落地。
- 如果你是一个传统行业的转型者,特别是医学、法律、制造、金融、物流等数据密集的领域,一定要重视AI工程化落地。
- 如果你是一位企业决策者,关注降本增效、提升核心竞争力与商业模式创新,请一定要重视AI工程化落地。
- 如果你是一位独立开发者,关注企业赋能、获取竞争机会,请一定要重视AI工程化落地。
在这里,不空谈技术,只聚焦: ✅ 真实可复用的AI落地案例 ✅ 哪些场景AI真能见效,哪些只是泡沫 ✅ 从0到1跑通一个AI应用的完整流程 ✅ 避开投入巨大却无回报的“技术坑”
💡 有时候, 一个流程的跑通,能帮你省下6个月试错成本; 一个避坑经验,能避免你烧掉几十万无用投入; 一个场景的启发,能直接开辟你的第二增长曲线。
如果你不甘于只做AI时代的“旁观者”,欢迎加入我们。 用工程化的思维,把AI变成你的竞争力、你的现金流、你的超车机会。



{kind=link}
大家一起来讨论