
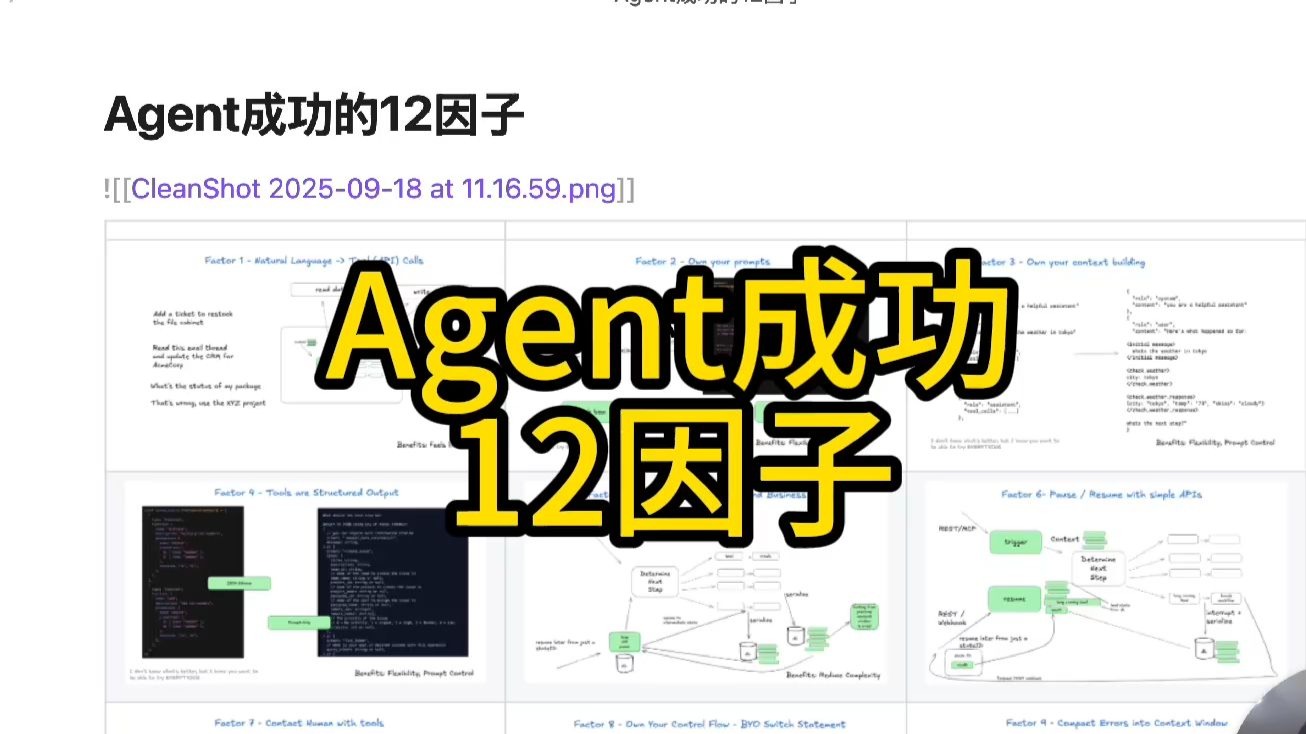
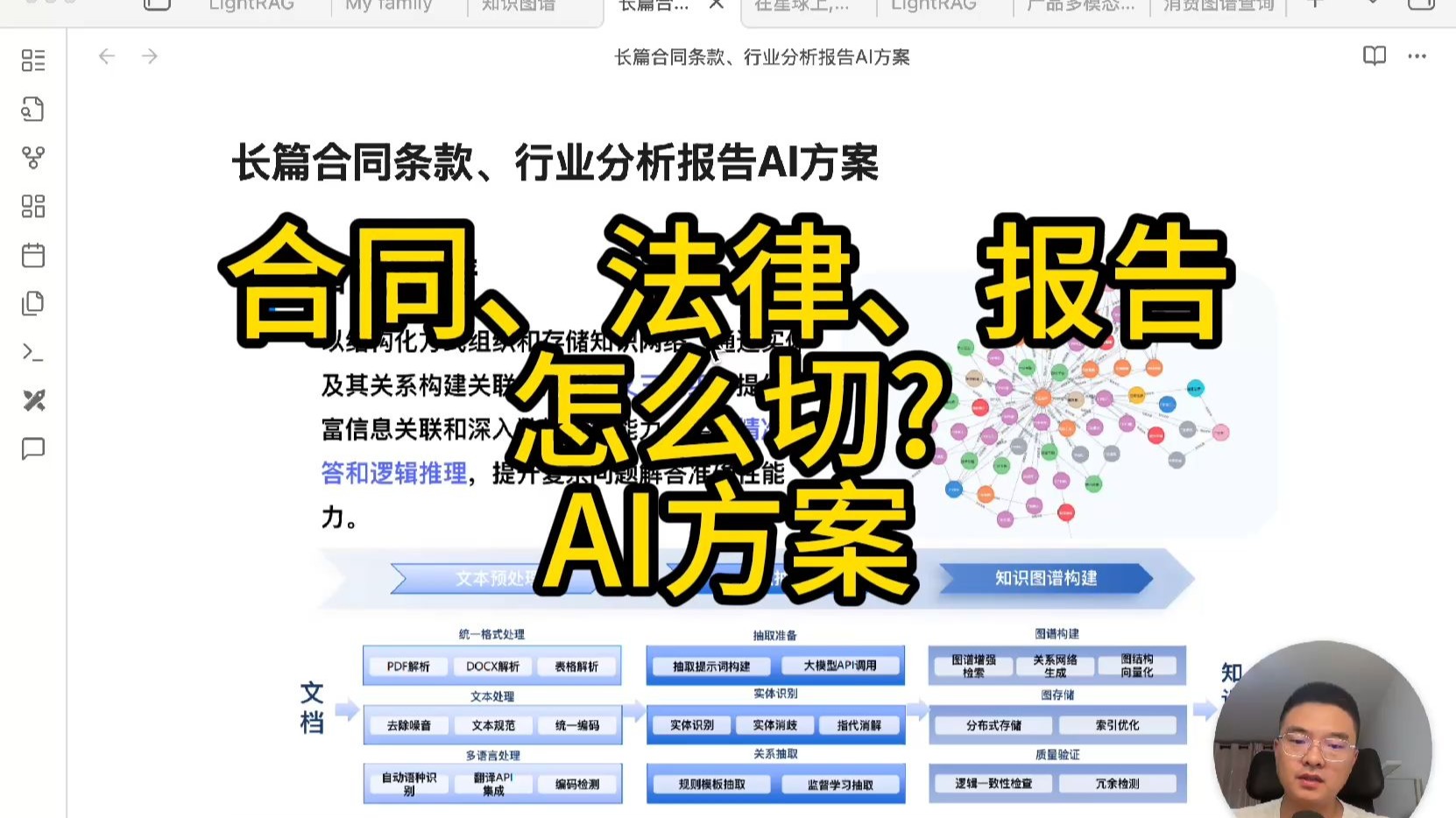
Table of Contents
使用图谱的有效方式
理解用户意图 → 选择模板 → 提取参数(AI擅长的NLP任务)
核心优势: 每次预制一个Cypher就是对一个场景的深入理解。
Cypher生成的致命问题
❌ 语法错误风险
AI可能生成:
MATCH (p:Person WHERE name = "马斯克" -- 缺少右括号
MATCH (p:Person)-[:CREATED_BY]→(o:Organization -- 箭头符号错误
MATCH (p:Persion) -- 拼写错误
- 问题:即使GPT-4也会犯低级语法错误
- 后果:查询直接报错,用户体验极差
❌ Schema幻觉问题
AI可能编造不存在的标签/关系:
MATCH (p:Person)-[:FOUNDED_BY]->(o:Company) -- 实际应该是CREATED_BY + Organization
MATCH (p:Person)-[:IS_FRIEND_OF]->(o:Person) -- 关系类型根本不在Schema里
- 问题:AI”自作聪明”创造新类型
- 后果:查询结果为空,用户以为没有数据
❌ 性能灾难
AI可能生成超低效查询:
MATCH (a)-[*5..10]-(b) -- 5-10跳遍历,可能导致数据库卡死
MATCH (a), (b), (c), (d) -- 笛卡尔积,数据量大了直接崩
WHERE a.name = "马斯克" OR b.name = "马斯克" OR c.name = "马斯克"
做图谱的思路
核心思路: 通过Schema约束的LLM抽取方法,让大模型在预定义的实体类型和关系类型范围内,生成结构化的JSON图谱数据。这种方法在准确性、通用性和可维护性之间取得了良好平衡。
示例查询:
CALL db.index.fulltext.queryNodes("entity_index", $query)
YIELD node, score
MATCH (node)-[r]->(neighbor)
RETURN node.name + ' ' + type(r) + ' ' + neighbor.name as text
LIMIT 5
Schema设计
节点标签(实体类型)
VALID_NODE_LABELS = [
"Person", # 人物:马斯克、乔布斯
"Organization", # 组织:特斯拉、苹果
"Location", # 地点:加州、北京
"Concept", # 概念:AI、区块链
"Document", # 文档:报告、论文
"Event", # 事件:发布会、并购
"Product" # 产品:iPhone、Model 3
]
关系类型
VALID_RELATION_TYPES = [
"WORKS_FOR", # 雇佣:马斯克 →WORKS_FOR→ 特斯拉
"LOCATED_IN", # 位置:特斯拉 →LOCATED_IN→ 加州
"RELATES_TO", # 相关:AI →RELATES_TO→ 机器学习
"MENTIONS", # 提及:文档 →MENTIONS→ 公司
"PART_OF", # 部分:加州 →PART_OF→ 美国
"CREATED_BY", # 创建:SpaceX →CREATED_BY→ 马斯克
"HAS_FEATURE" # 特征:产品 →HAS_FEATURE→ 功能
]
Prompt模板
prompt = f"""
You are a Knowledge Graph extraction engine.
Extract nodes and relationships from the text.
Allowed Node Labels: {VALID_NODE_LABELS}
Allowed Relationship Types: {VALID_RELATION_TYPES}
Return JSON format only:
nodes],
"edges": [source]
}}
Input Text:
{text}
"""
使用示例
输入文本
"Elon Musk founded SpaceX in 2002. The company is headquartered in Hawthorne, California."
LLM输出
{
"nodes": [
{"id": "Elon Musk", "type": "Person"},
{"id": "SpaceX", "type": "Organization"},
{"id": "2002", "type": "Event"},
{"id": "Hawthorne", "type": "Location"},
{"id": "California", "type": "Location"}
],
"edges": [
{"source": "Elon Musk", "target": "SpaceX", "type": "CREATED_BY"},
{"source": "SpaceX", "target": "2002", "type": "RELATES_TO"},
{"source": "SpaceX", "target": "Hawthorne", "type": "LOCATED_IN"},
{"source": "Hawthorne", "target": "California", "type": "PART_OF"}
]
}
咱们的社群
星球中有开箱即用的源码、解决发难、讲解视频、提示词,以及落地经验.
欢迎加入我们,思考技术对商业的价值.

如果你有场景和困难, 欢迎找我聊聊AI
AI咨询、AI项目陪跑.
我的微信: leigeaicom

{kind=link}
大家一起来讨论