
Table of Contents
企业要不要建知识图谱呢?今天我们把这个事情讲透
图谱解决的 14 个 RAG 复杂失效问题 (懒得看的话就不用每个都看,哈哈 直接看列表后的总结)
- 歧义性 (Ambiguity): 无法区分具有相同名称但含义不同的实体(例如,“苹果”是公司还是水果)。
- 多跳推理 (Multi-Hop Reasoning): 无法连接分布在不同文档或片段中的多个事实来回答复杂问题。
- 幻觉 (Hallucinations): 模型在没有检索到足够证据时凭空捏造答案。
- 上下文窗口限制 (Context Window Limits): 无法将所有相关文档都放入 LLM 的上下文窗口中,导致信息丢失。
- 信息碎片化 (Information Fragmentation): 关键信息散落在多个不连续的文本块中,传统检索难以整合。
- 隐式关系 (Implicit Relationships): 文本中未直接说明但在逻辑上存在的实体间联系(如“作者”与“书”的关系)。
- 结构丢失 (Structural Loss): 传统的文本分块(Chunking)破坏了文档原有的层级结构(如标题、表格关系)。
- 术语不匹配 (Vocabulary Mismatch): 用户查询的词汇与文档中的专业术语不一致(如同义词问题)。
- 逻辑一致性 (Logical Consistency): 当不同来源的信息相互矛盾时,无法有效解决冲突。
- 时序推理 (Temporal Reasoning): 难以理解和处理事件发生的先后顺序或时间限制。
- 复杂聚合 (Complex Aggregation): 难以回答需要统计、汇总或计算的问题(如“列出所有分公司的总收入”)。
- 可解释性差 (Lack of Explainability): 无法提供检索路径或推理过程,用户难以信任答案。
- 冷启动问题 (Cold Start): 对于新引入的领域知识,向量模型可能缺乏足够的语义理解。
- 噪声干扰 (Noise/Irrelevance): 向量检索容易召回语义相似但实际无关的内容,干扰模型回答。
总结: 图谱就是解决信息碎片化问题,让信息在给到模型之前前置的聚合起来
对比效果
以西游记为案例来看一下知识图谱的效果,我问猪八戒与红孩儿有关系吗?
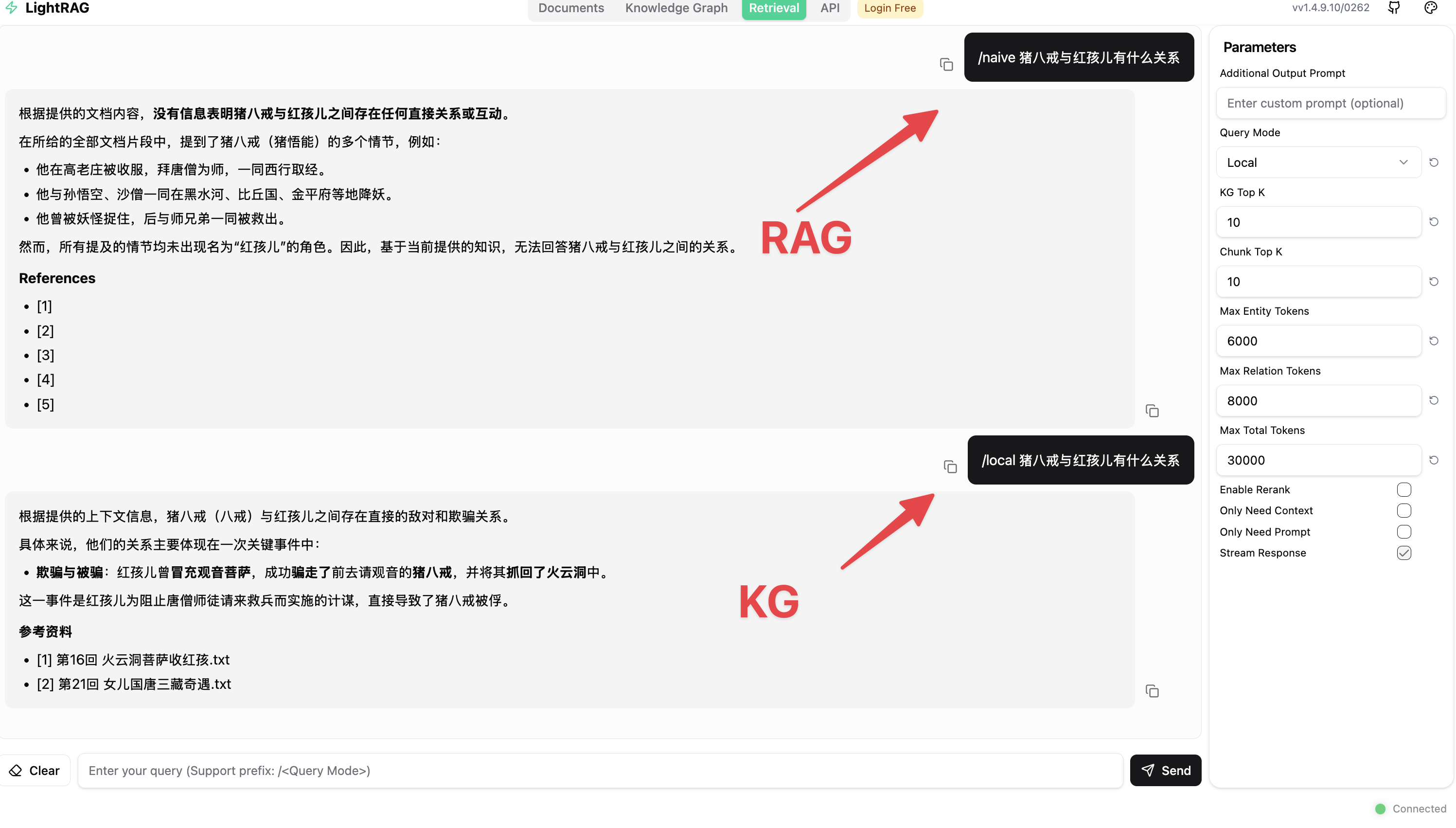 在这里可以直观地看到,有了知识图谱,很多关联关系就不是碎片化的,可以把它们整合起来。
在这里可以直观地看到,有了知识图谱,很多关联关系就不是碎片化的,可以把它们整合起来。
判断是否要建图谱的关键
判断是否要建图谱的关键是你是否会用图谱。

比如,如果你使用Cypher语句去查玉皇大帝和蜘蛛精之间到底有什么关系,他们的链路是怎么串联起来的?如果你这么用图谱,在检索方面来讲是错误的。
原因是当你在查询中写下 MATCH (a)-[*]->(b) 这种不负责任的代码时,你实际上是在让数据库遍历宇宙。
有一个社交关系理论叫六度理论,它和图谱查询的逻辑是一样的。如果图谱不做限制,逻辑是这样的:
-
1 跳:A 认识 10 个人。
-
2 跳:这 10 个人每人又认识 10 个人(100 个节点)。
-
3 跳:1,000 个节点。
-
…
-
6 跳:1,000,000 个节点。
这就是指数级增长。你的CPU和内存是扛不住的。
更可怕的是“语义漂移”(Semantic Drift)。 机器可能会找到这样一条路:“A是B的同事 -> B喜欢吃苹果 -> 苹果产自烟台 -> 烟台有个名人叫C”。 虽然路径通了,但在业务上,A和C有一毛钱关系吗? 没有。这种垃圾数据喂给 LLM,只会产生更严重的幻觉。
所以不是越长的链路,对模型的效果越好.
怎么用图谱
在大模型时代,我们需要给到大模型多跳的、有关联的关系。最佳实践是2到3度的关系就可以了
传统能想到的是广度优先算法,我们以这个问题为例:太上老君和黄袍怪有什么关系?
传统算法是先以太上老君为节点,然后进行广度优先搜索,每一个节点都连跳两度。这样节点数是非常多的。
对于模型来讲可以进行优化,这个优化的算法叫做:双向搜索(Bidirectional Search)。
(星球中我还介绍了此问题的扩展和解决方案: 图谱KG-多跳推理爆炸问题与解决方案: https://articles.zsxq.com/id_93r15eo5uaxg.html)
这个算法是说,我们从两个重要的实体分别找到它们的一度关系,然后直接给到模型。模型看到两个一度关系之间有关联的信息时,就会自动总结成一个3度的关系
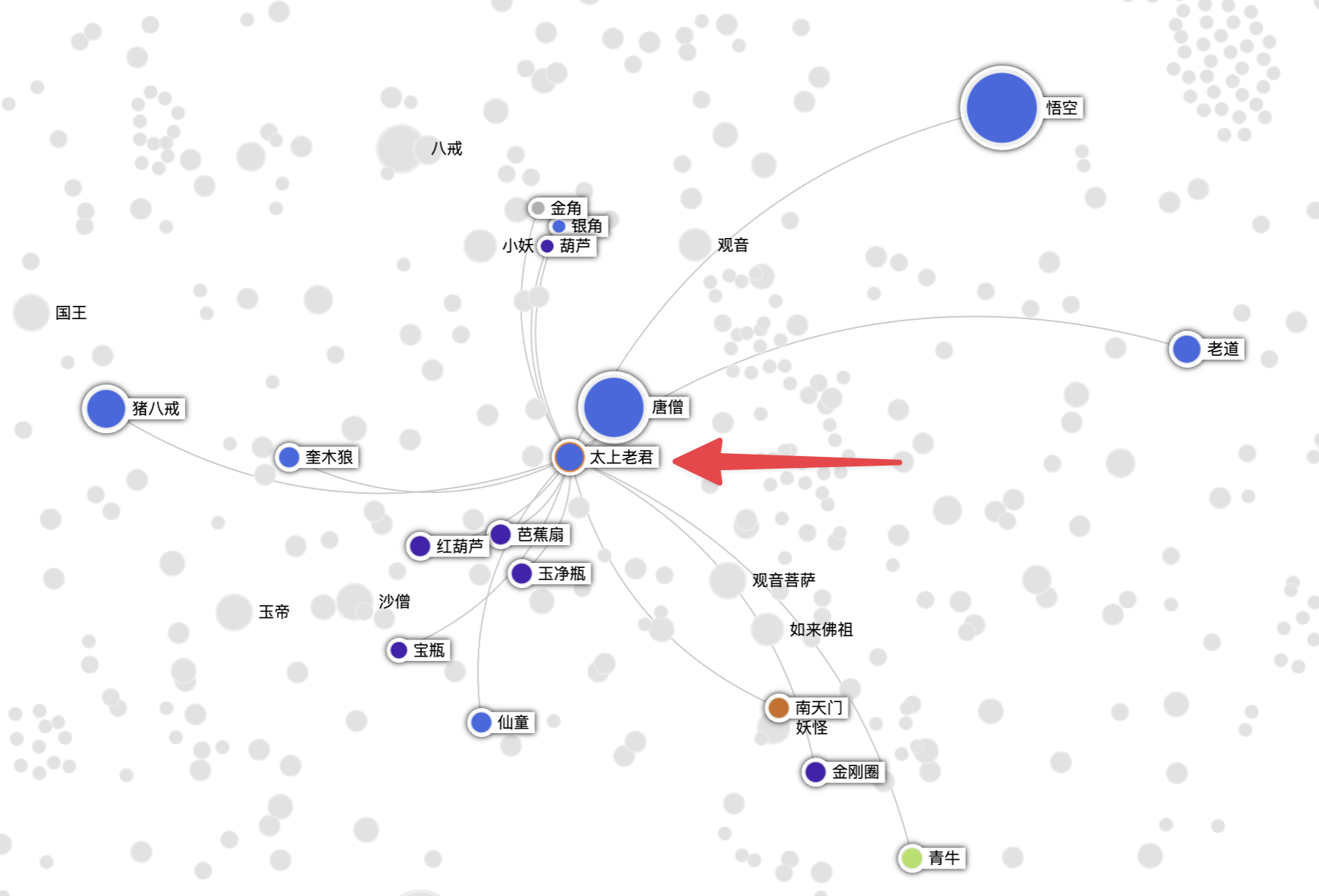
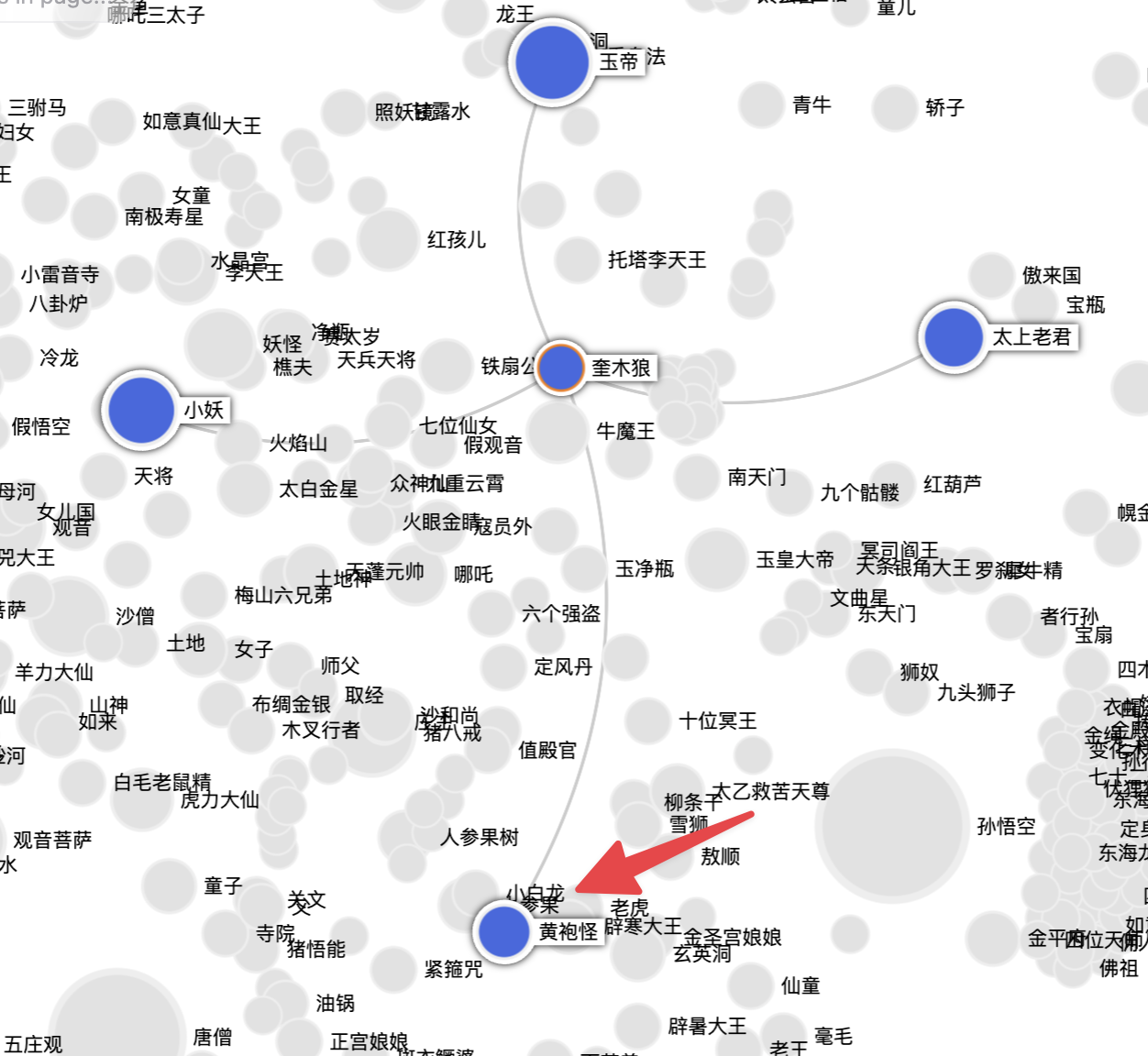
太上老君和黄袍怪都跟奎木狼这个实体有关系,所以在查询时可以找到这个相关性关系
怎么构建图谱
对于特定场景、特定需求方向的图谱,我们一般使用顶层的本体设计
(星球中详细介绍《防止图谱的构建混乱“意大利面条问题”-本体设计》:https://articles.zsxq.com/id_132ego6i3jcw.html)
大致的逻辑是,我们先把类型和关系都确定下来。当模型进行抽取的时候,就直接抽取此类型下的实体和此类型关系下的关系。
图谱的过度设计: 但这样会有一个问题,构建图谱本身就变成了一个特别重型的工程。对于所有重型工程,顶层设计都要做好。因为不管是在构建图谱的过程中,还是新增语料融合到现有图谱的过程中,你一定要关心这个图谱用于哪个场景、哪个需求,怎么设计实体,怎么设计实体之间的关系。所以就会产生一个最重要的问题,叫做过度设计。
这是之前做图谱项目,包括以前NLP项目都面临的一个非常严重的问题。很多图谱基本上5年以下打磨的都没法用。
最佳的构建图谱方案是先确定好实体有哪些比较大的分类,关系先不去定:
不要试图穷举所有类型。遵循 “奥卡姆剃刀” 原则,只定义业务必须的“骨架”。
- 实体 (Entities):保持粗粒度。
- ✅ 推荐:
[Person, Organization, Product, Event, Document, Concept] - ❌ 避免:
[CEO, Supplier, SaaS_Software, Q3_Financial_Report](这些应作为属性或描述存在)
- ✅ 推荐:
- 关系 (Relations):半开放式策略。
- 硬约束:禁止使用无意义的
related_to。 - 软引导:在 Prompt 中引导 LLM 使用具体的动词(如
acquired,developed,criticized),允许自然语言的多样性。
- 硬约束:禁止使用无意义的
所以这里边对我们有一个要求: 直接复用 LightRAG 或类似框架的架构,但必须替换其默认提取 Prompt:
- Prompt 改造重点:
- 注入关注点 (Focus List):告诉 LLM 你只关心哪些领域的实体
未来如果实体要进行更细粒度的分类,就给它打上一个属性类型,理解成一个tag标签就行。 未来如果是关系层面,就使用模型将相同语义表达的关系进行合并。
这样逐渐地,你的图谱就慢慢成型了。
那要不要建图谱呢
已经说了图谱有这么多好的办法,也找到了解决方案。那建图谱有没有别的困难阻碍我们呢?
构建成本(Indexing Cost)依然是拦路虎
虽然它叫 “Light”(轻量),但那是相对于微软原版 GraphRAG 这种“重型坦克”而言的。
- 对比向量库: 普通 RAG 只需要
切片 -> 向量化 -> 存入,速度极快,成本极低。 - 对比 LightRAG: 它依然需要 LLM 介入来提取实体(Entities)和关系(Relationships)并构建知识图谱。这意味着在建立索引阶段,依然需要消耗大量的 Token 和时间。
- 结论: 对于很多只需“简单问答”的场景,这部分额外的时间和金钱成本被认为是“不必要的”。
工程生态尚未成熟(Production Ready?)
目前 LightRAG 更多是以学术论文或开源 Demo 的形式存在,而不是成熟的商业级 SDK。
- 缺乏集成: 它是独立的,还没被完美集成到 LangChain、LlamaIndex 或各大向量数据库的一键解决方案中。
- 技术待成熟: 所有图谱都是通过模型直接抽取就生成的,它并没有一个审核的一些策略。所以集成如果是lightRAG这种方式的话,去做图谱的话,一定要补充人工的审核机制。
- 运维难度: 维护一个向量数据库很简单,但维护一个“图数据库 + 向量数据库”的混合体(Dual-level retrieval),对运维团队的要求高了一个量级。如果数据更新了,图谱怎么增量更新?这在工程上是很麻烦的。
“够用就好”定理(边际效应递减)
这是最现实的原因。
- 80% 的场景: 普通的向量检索(Vector RAG)加上一个好点的重排序(Rerank)模型,已经能解决 80%-90% 问题了。
- 剩下的 20%: 只有那些需要跨文档推理、全局概览(比如“总结全书的人物关系”)的复杂场景,才真正需要 GraphRAG。
- 现状: 大多数人试用后发现,“为了提升 10% 的效果,我要多花 200% 的精力去维护图谱”,于是就放弃了。 (所以这块还是跟我们的ROI有关系的)
可跑起来的代码
我使用代码把整个西游记全文通过代码和本地embedding的方式在本地构建起来了
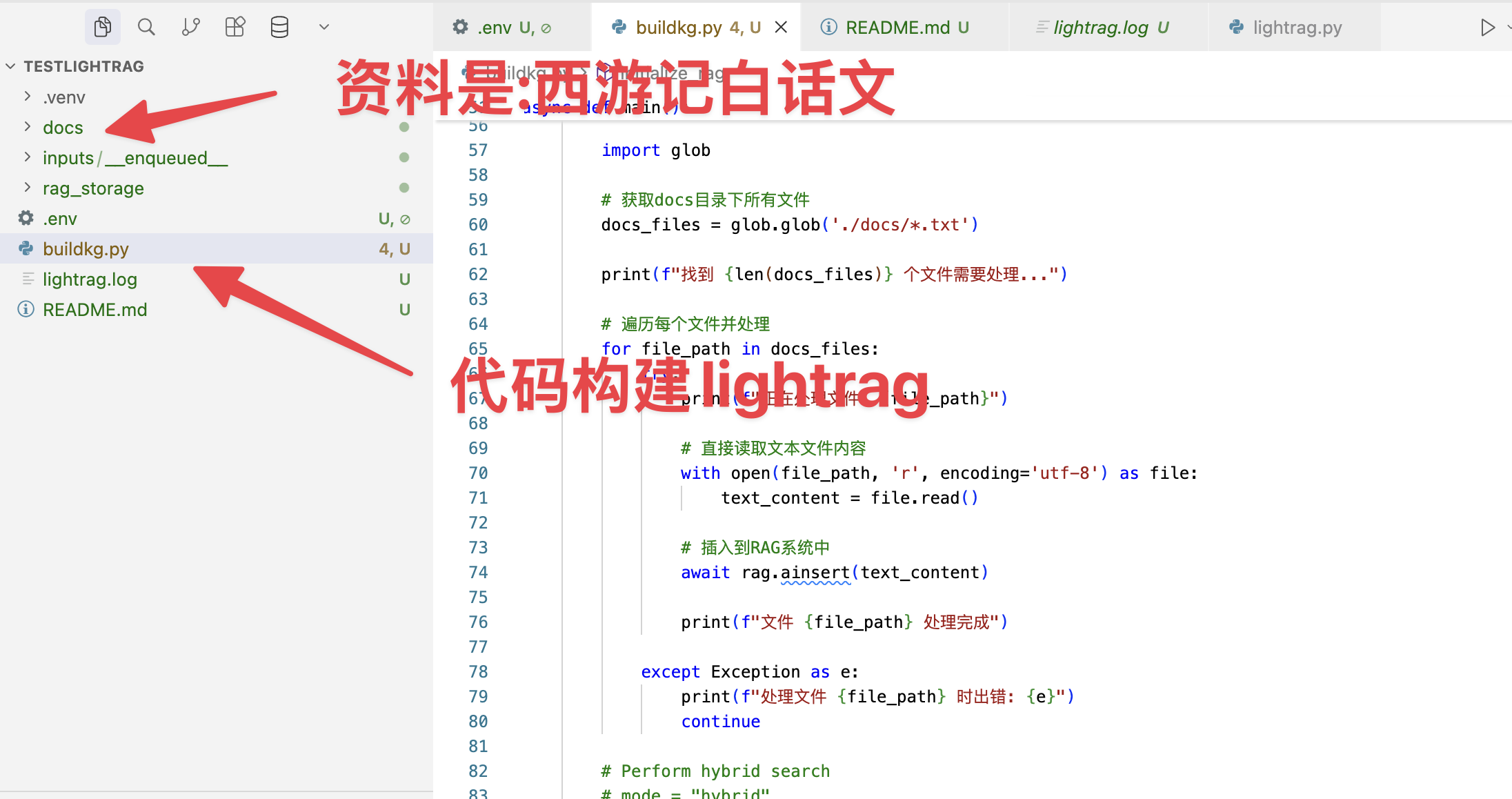
然后启动docker,加载这个命令,你就可以看到跟我演示项目一样的效果了,也省去了自己构建图谱的时间。因为整个图谱我构建一共花了2到3个小时
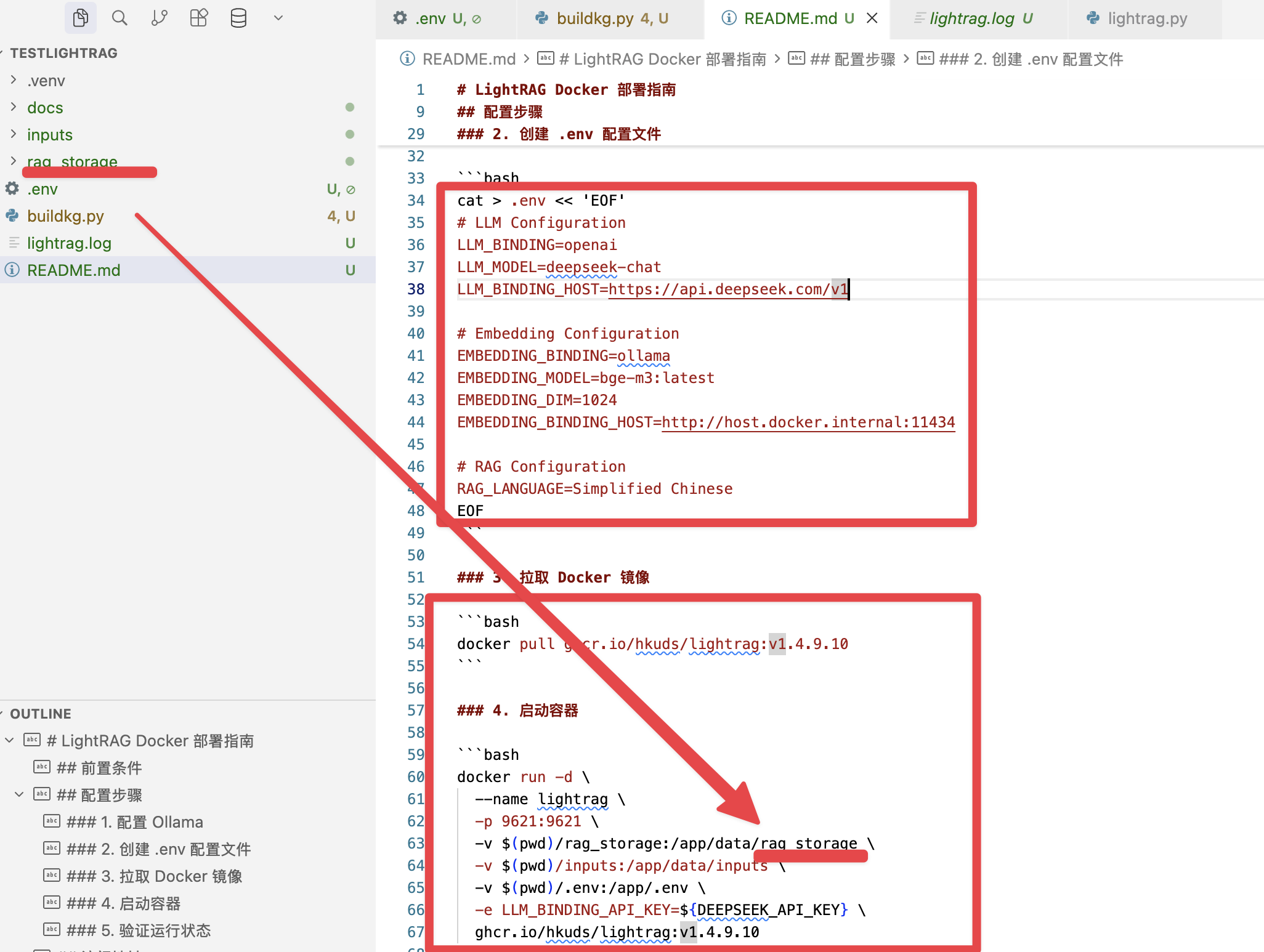
源码
源码都在星球中了.
咱们的社群
星球中有开箱即用的源码、解决发难、讲解视频、提示词,以及落地经验.
欢迎加入我们,思考技术对商业的价值.

如果你有场景和困难, 欢迎找我聊聊AI
AI咨询、AI项目陪跑.
我的微信: leigeaicom


{kind=link}
大家一起来讨论