
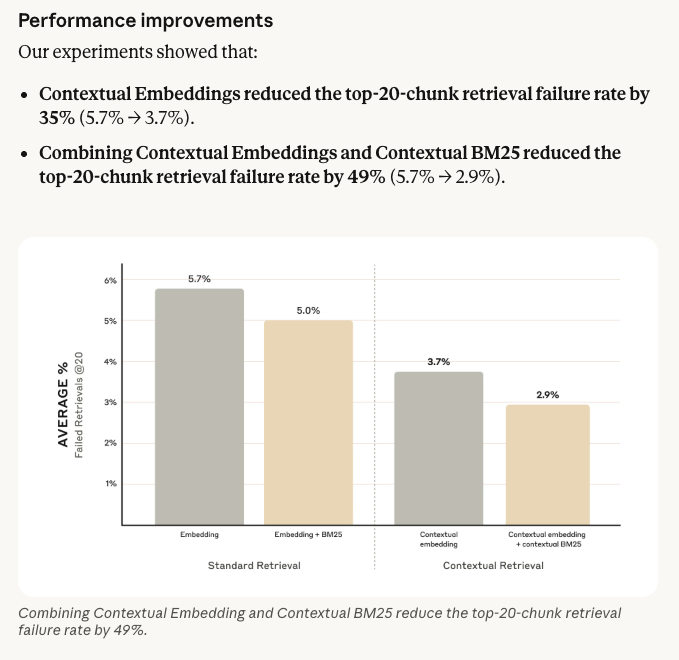
这是一种被低估的RAG方法。 它可以让你的召回失败率降低49%。
 原文: https://www.anthropic.com/engineering/contextual-retrieval
原文: https://www.anthropic.com/engineering/contextual-retrieval
方法介绍
如果你一直在做RAG相关工作,对它一定不陌生。它是Anthropic在24年9月份提出的一种方法——上下文检索(Contextual Retrieval)
按句子拆分:
ACME Corp 2023年第二季度财务业绩报告。 本季度公司面临宏观经济挑战,但总体表现稳健。 特别是标准产品部门表现优异。 收入比上一季度增长了 3%。 然而,云服务部门的利润率略有下降,主要由于基础设施投资增加。 CEO Jane Doe 表示:”我们要加倍投入研发,以确保长期竞争力。” 关于未来的展望,我们预计下个季度会有温和的增长。
假设这个问题: 哪个季度增长了?
收入比上一季度增长了 3%。
本季度公司面临宏观经济挑战,但总体表现稳健。
关于未来的展望,我们预计下个季度会有温和的增长。
这些召回的片段,根本没有办法回答用户的问题,因为它缺乏全文的上下文信息。
如果需要让它有全文上下文信息,并且可以稳定召回,我们就需要把上下文信息补充进去。比如:
本季度ACME Corp收入环比增长3%,背景为宏观经济挑战下标准产品部门表现优异,体现整体稳健态势。
收入比上一季度增长了 3%。
2023年第二季度,ACME Corp标准产品部门表现优异,收入环比增长3%,成为本季度亮点。
特别是标准产品部门表现优异。
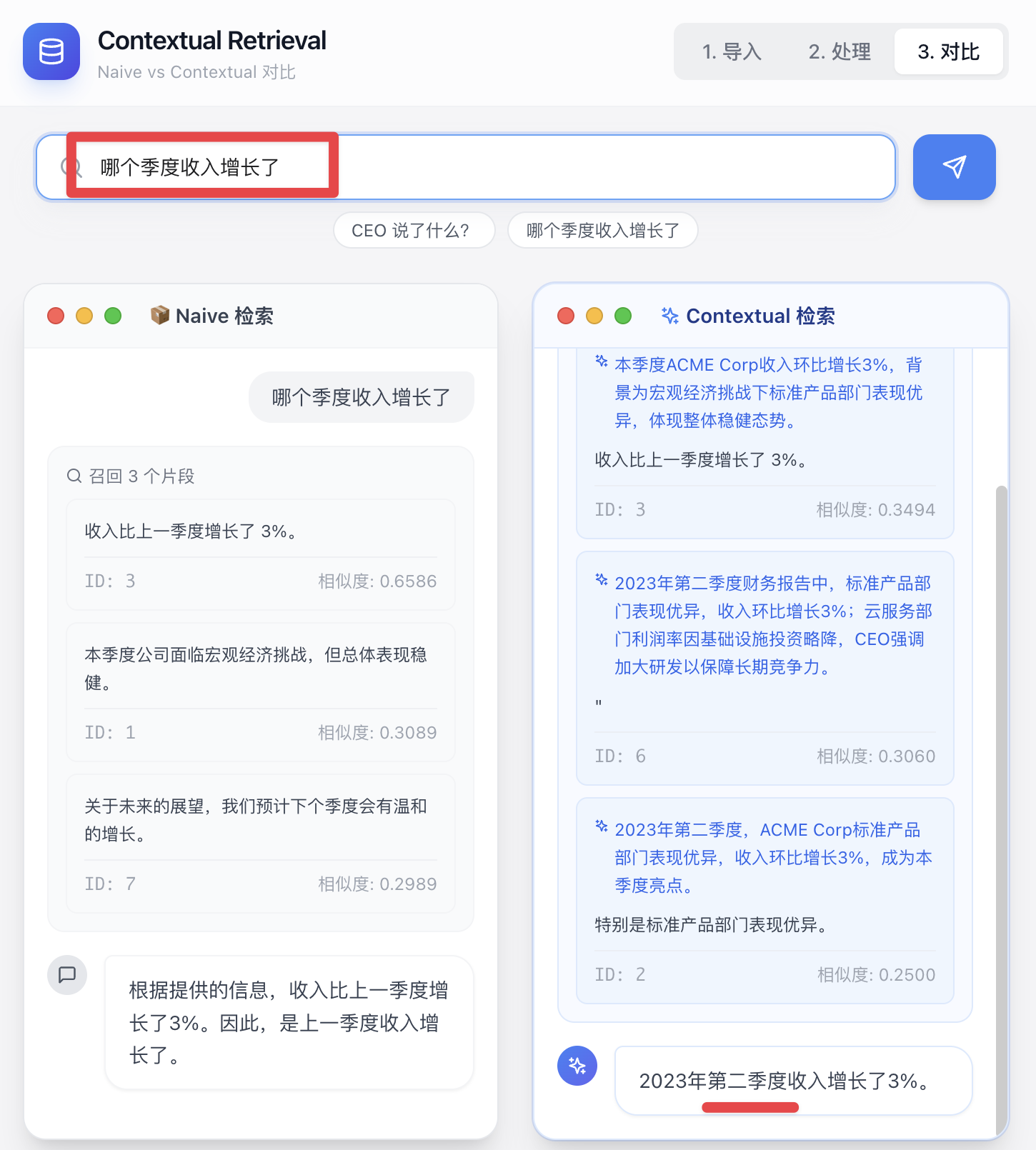 上面被补充的这部分上下文信息,其实是我们使用模型生成的。通过这样的方式,我们可以把模型生成的上文信息补充到现有片段里。因为片段本身是零碎的,实际上缺少很多上文信息,这就补全了我们上下文信息缺省的问题。
上面被补充的这部分上下文信息,其实是我们使用模型生成的。通过这样的方式,我们可以把模型生成的上文信息补充到现有片段里。因为片段本身是零碎的,实际上缺少很多上文信息,这就补全了我们上下文信息缺省的问题。
为什么今天还讲
但今天为什么把这个技术拿出来讲呢?因为它仍然是一个非常被低估的方法。而且时间过去了一年多,从模型能力来看,这个方法的可行性大大提升了。
![[被低估的RAG方法 2025-12-27 10.47.34.excalidraw]]
随着现在模型变得越来越强,以前生成准确的摘要信息,必须依靠大参数模型。尤其在24年底或25年初,DeepSeek那波浪潮没有起来之前,这里边的限制包括上下文大小不足、大模型费用比较高。当然后来有了缓存技术,降低了一些模型成本。但从整体的准确率和响应速度来讲,它还没有达到工程级或工业级的应用水平。
现在小模型对于摘要总结已经有很大的优势了。
摘要评估: https://www.siliconflow.com/articles/zh-Hans/best-open-source-llms-for-summarization
模型选型: https://ollama.com/alibayram/Qwen3-30B-A3B-Instruct-2507
embedding选型: https://ollama.com/library/bge-m3
有了这些之后,我们的应用就可以搭建起来了。
我搭建的这个源码
完全本地搭建.
因为很多朋友还不知道如何做一个后端是Python、前端通过Next.js这个React框架去实现的联动程序。所以我结合后端Python,前端Next.js,中间使用FastAPI进行交互,把整个项目搭建起来了,使用的全都是开源技术。以我的Mac电脑来讲,是可以完全本地跑起来的应用。
使用到的技术: 前端: nextjs
后端: 提供接口服务:fastapi 模型框架:langchain 向量库框架:chroma
模型: 本地LLM:qwen32b-3a 本地embedding: bge-m3
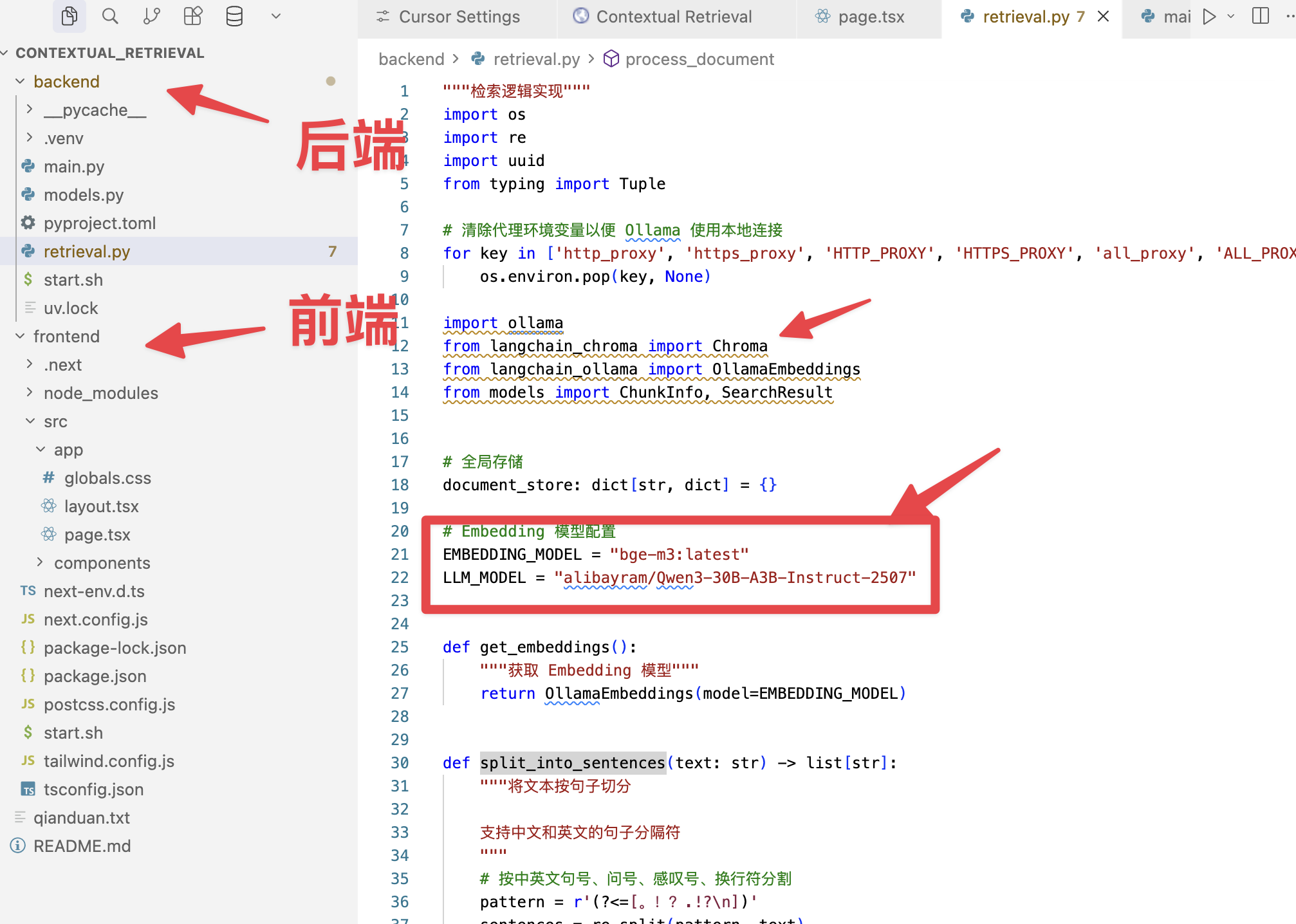
当对整个项目的架构越来越了解,结合AI Coding的话,我们就可以慢慢把它转成一个生产级、服务于更多人的项目。
源码
源码都在星球中了.
咱们的社群
星球中有开箱即用的源码、解决发难、讲解视频、提示词,以及落地经验.
欢迎加入我们,思考技术对商业的价值.

如果你有场景和困难, 欢迎找我聊聊AI
AI咨询、AI项目陪跑.
我的微信: leigeaicom



{kind=link}
大家一起来讨论