
Table of Contents
一、“RAG 已死”是一个伪命题:核心在于数据结构的差异
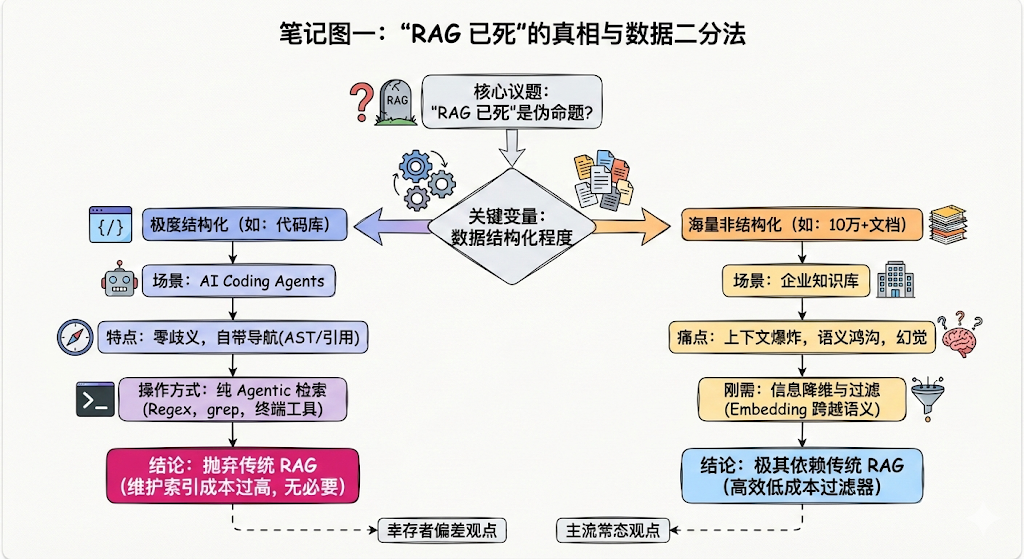
目前业界(尤其是 AI 编程工具领域)流传的“传统 RAG 已死”,实际上是特定场景下的幸存者偏差。是否使用传统 RAG(即文本切块 + 向量检索),完全取决于数据的结构化程度。
RAG 全称为 Retrieval-Augmented Generation,即检索增强生成,它结合了检索和生成的能力,为文本序列生成任务引入外部知识。
1. 为什么 AI Coding Agents 抛弃了传统 RAG?
代码是极度结构化的数据,使用纯 Agentic 检索(直接系统命令 / AST 解析)具有压倒性优势:
- 零语义歧义: 代码标识符和语法是绝对精确的,不需要依赖向量模型去猜测“同义词”,直接使用正则(Regex)或终端工具(如
grep、cat)效率极高。 - 自带导航地图: 代码库拥有严谨的文件树和
import引用关系。Agent 可以通过目录树或抽象语法树(AST)精准制导,实现确定性的“图导航”。 - 规避索引维护噩梦: 代码在开发中高频变动,实时重建 Chunking 和 Embedding 的时间成本和计算成本过高。
2. 为什么海量非结构化数据(10 万+ 文档)依然极其依赖传统 RAG?
在面对海量企业知识库(如规章制度、研究报告、历史工单)时,抛弃向量检索会让 Agent 直接崩溃:
- 致命的上下文爆炸(Context Window Explosion): 如果让 Agent 像遍历代码一样去读取几十万份文档,大模型的上下文会在瞬间被无关信息塞满,不仅会导致极高的 API 成本,还会引发严重的“迷失在中间(Lost in the Middle)”幻觉。
- 信息降维与过滤的刚需: 传统 RAG 本质上是一个极度高效的低成本过滤器。它利用底层向量数据库的算力,在将信息喂给极其昂贵的大模型之前,先完成信息的降维,精准提取出最相关的几千个 token。
- 跨越语义鸿沟: 非结构化文本充满隐喻和模糊表达,只有依靠 Embedding 才能实现概念级别的匹配(例如搜“星战飞船”能召回“千年隼”)。
二、传统 RAG 的核心痛点:语义切分不完整
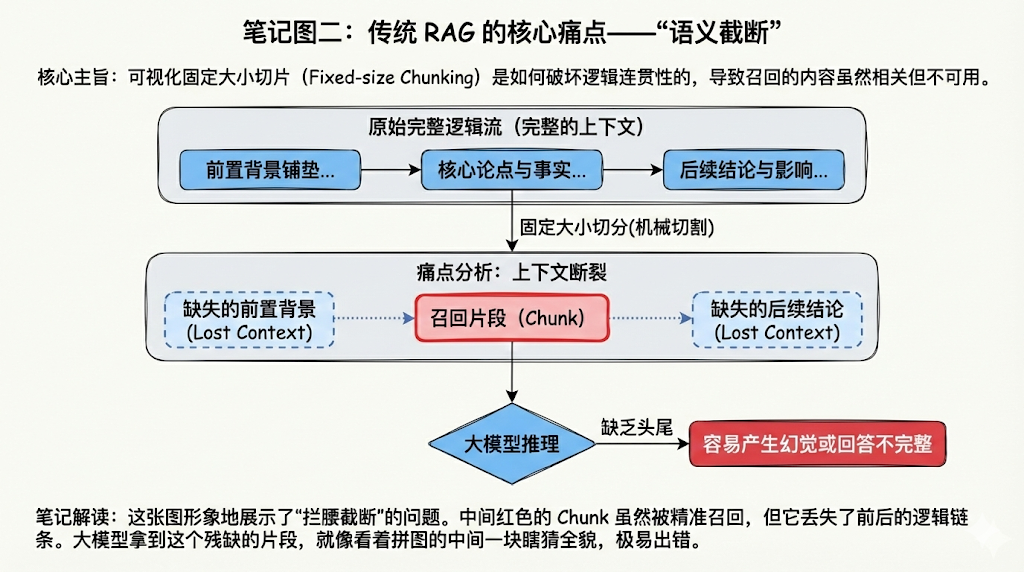
尽管传统 RAG 解决了上下文爆炸的问题,但它引入了一个新的致命缺陷:固定大小的切分(Fixed-size Chunking)往往会破坏逻辑的连贯性。
单次向量召回的准确率虽然尚可,但召回的片段(chunk)可能是一段被拦腰截断的话,导致大模型在推理时缺乏必要的前置背景或后续结论(上下文断裂)。
三、破局之道:高阶动态上下文扩充机制
为了在“低成本抗爆炸(传统 RAG 优势)”和“获取完整逻辑块(Agentic 检索优势)”之间取得平衡,我们推演了以下几种架构策略,并对它们的实战可行性进行了严格甄别。
1. Contextual Retrieval(上下文增强切块 / 语境丰富化)
核心思路是增强命中质量,例如:从一个片段生成若干问题或语境提示,用于扩大召回覆盖面。
2. 基础解法:Small-to-Big / Sentence Window
- 父子块(Small-to-Big): 对细粒度(子)切片进行精准向量检索,命中后直接向模型返回其所属的大粒度(父)文本块。
- 滑动窗口(Sentence Window): 以句子为单位检索,命中后动态向前后延伸固定的句子数量(如前后各加 3 句)拼接返回。
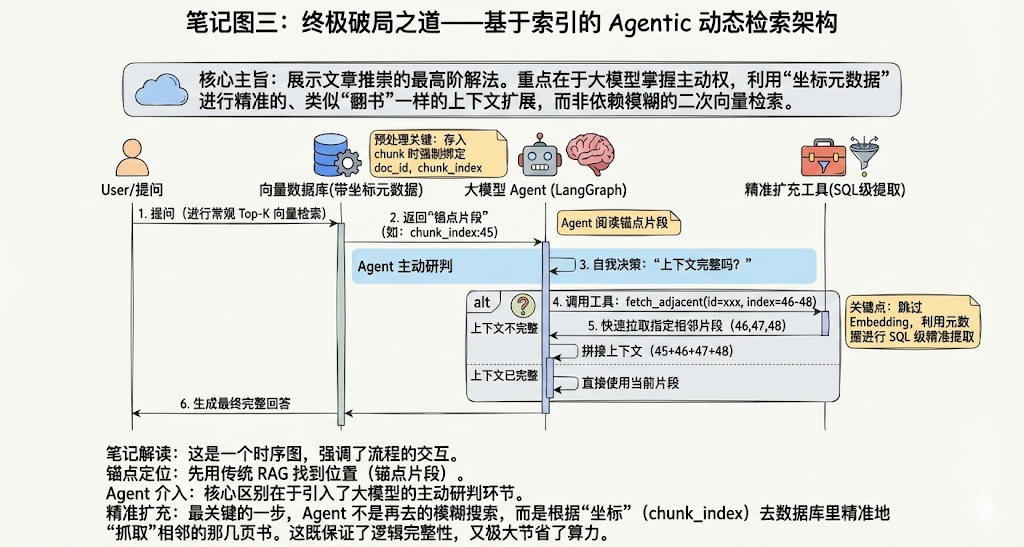
3. 终极架构解法:基于索引的 Agentic 动态检索(Agentic Retrieval)
这是最贴合真实业务逻辑的高阶解法:由大模型掌握绝对主动权,像“翻书”一样动态在向量库中抓取相邻片段。
架构运转逻辑:
- 带有“坐标”的元数据入库: 在数据处理阶段,文本依然被切分为带有重叠(overlap)的固定大小片段。但关键在于,存入底层向量数据库(如 Supabase 的
pgvector)时,必须强制绑定严格的坐标元数据,例如doc_id、chunk_index、total_chunks。 - 第一轮寻路(纯向量召回): 针对用户问题,系统执行常规的 Top-K 向量相似度检索,找到“锚点片段(Anchor Chunk)”(例如
chunk_index: 45)。 - Agent 主动决策(工作流介入): 大模型在 LangGraph 的节点中阅读该片段,自行判断信息是否完整。如果发现缺失上下文,它会决定调用预设的扩展工具。
- 基于元数据的精准扩充: Agent 调用的不再是模糊的“文本读取”或“向量匹配”,而是调用带有确切索引的工具,例如
fetch_adjacent_chunks(doc_id="xxx", start_index=46, end_index=48)。 - SQL 级精准提取: 系统收到指令后,跳过所有 Embedding 和相似度计算,直接通过
pgvector的元数据过滤(metadata filtering),将第 46、47、48 个片段快速拉出并拼接进大模型上下文。
核心优势:
- 彻底规避让 Agent 直接解析复杂原始文件的“荒谬感”。
- 完美解决语义截断问题,逻辑链条的完整性由 Agent 动态判断并补全。
- 大幅节省 token 消耗,因为每一次扩充都是极度精准的索引调用。
咱们的社群
星球中有源码、解决方案、提示词,以及落地经验.
欢迎加入我们,思考技术对商业的价值.

欢迎找我合作
AI咨询、AI项目陪跑、AI项目落地.
我的微信: leigeaicom


{kind=link}
大家一起来讨论