
Table of Contents
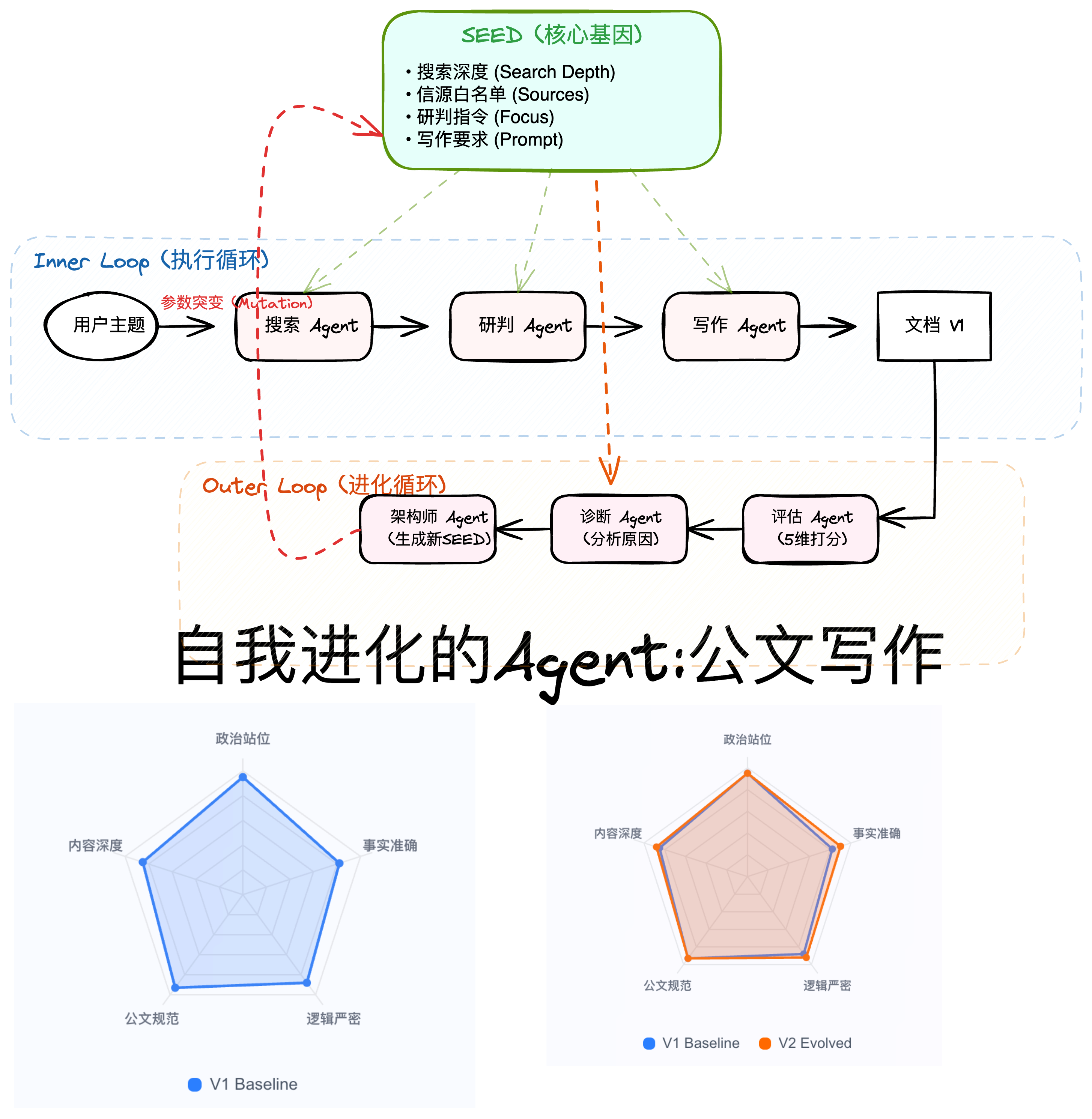
AI系统写完第一版文档后,自己能发现问题、分析原因、调整策略,然后生成更好的第二版。这就是我们今天要介绍的设计方法–自我进化文档生成系统。
本文将详细介绍如何构建一个能够自我改进的AI Agent系统,以政府公文写作为例,展示完整的设计思路、架构实现和代码细节。
一、核心设计理念:双循环架构
传统AI应用是”一次性”的:输入→处理→输出。但真正的智能应该具备自我反思和持续改进的能力。
1.1 Inner Loop(内循环):基础执行流程
用户输入主题
↓
搜索Agent:检索相关资料
↓
研判Agent:分析核心要点
↓
写作Agent:生成公文
↓
输出V1文档
这是标准的RAG(检索增强生成)流程,但这只是第一步。
1.2 Outer Loop(外循环):自我进化机制
V1文档
↓
评估Agent:5维度打分 → 找出弱点
↓
诊断Agent:分析根本原因
↓
架构师Agent:生成新的"基因"(SEED参数)
↓
重新执行Inner Loop(用新参数)
↓
输出V2文档(进化后的版本)
关键洞察:系统的行为由一组”可变参数”(SEED)控制,通过调整这些参数,我们实现了系统的自我进化。
二、SEED设计:系统的”基因密码”
SEED是整个进化机制的核心,它定义了系统如何搜索、如何分析、如何写作。
2.1 SEED数据结构
// lib/types.ts
export interface GovDocSEED {
searchDepth: number; // 搜索深度(5-20)
sourceWhitelist: string[]; // 信源白名单
focusDirective: string; // 研判指令
writingRequirements: string; // 写作要求(完整提示词)
}
注意: 后边这个种子GovDocSEED将会被动态调整
2.2 初始SEED(V1 Baseline)
const v1Seed: GovDocSEED = {
searchDepth: 2,
sourceWhitelist: ['全网'],
focusDirective: '通用概述',
writingRequirements: `写作要求:
1. 结构清晰,逻辑严密
2. 字数控制在800-1200字
请直接输出公文内容,不要额外说明。`
}
这是一个”泛化”的基线配置,故意设置得比较简单,给进化留出空间。
2.3 进化后的SEED(V2 Evolved)
系统根据V1的问题自动调整参数:
// 示例:诊断发现"事实准确性"和"内容深度"不足
const v2Seed: GovDocSEED = {
searchDepth: 15, // 增加搜索深度
sourceWhitelist: ['政府官网', '统计局', '权威智库', '央媒'], // 限制权威信源
focusDirective: '数据驱动+深度问题剖析', // 更明确的研判方向
writingRequirements: `写作要求:
1. 必须引用具体数据,标注来源
2. 加强问题分析的深度和逻辑推导
3. 提出的建议需具体可操作,包含实施步骤
4. 字数控制在1000-1500字
5. 论证严谨,无跳跃推理
请直接输出公文内容,不要额外说明。`
}
设计亮点:writingRequirements 是动态生成的完整提示词,不是简单的参数拼接,而是由AI根据问题诊断重新设计。
三、多Agent协作架构
系统由6个专业Agent组成,各司其职。
3.1 搜索Agent:信息检索
// lib/agents.ts
export async function searchAgent(
topic: string,
seed: GovDocSEED
): Promise<SearchResult[]> {
const tvly = tavily({ apiKey: process.env.TAVILY_API_KEY });
// 根据信源白名单调整搜索策略
let searchQuery = topic;
if (seed.sourceWhitelist.includes('政府官网')) {
searchQuery += ' site:.gov.cn OR site:stats.gov.cn';
}
const response = await tvly.search(searchQuery, {
maxResults: seed.searchDepth,
searchDepth: seed.searchDepth > 10 ? 'advanced' : 'basic',
});
// 根据白名单过滤结果
return filterByWhitelist(response.results, seed.sourceWhitelist);
}
技术细节:
- 使用Tavily API进行真实网页搜索
- 根据SEED的
searchDepth和sourceWhitelist动态调整 - 实现信源过滤(优先政府官网、统计局等权威来源)
3.2 研判Agent:深度分析
这是系统的”大脑”,负责从海量搜索结果中提炼核心观点。
export async function insightAgent(
topic: string,
searchResults: SearchResult[],
seed: GovDocSEED
): Promise<WritingGuidance> {
const prompt = `你是一个专业的政策研判Agent。基于以下搜索结果,按照指定的研判方向进行深度分析:
主题:${topic}
研判指令:${seed.focusDirective}
搜索结果:
${searchResults.map((r, i) => `[${i + 1}] ${r.title}\n来源:${r.source}\n摘要:${r.snippet}`).join('\n\n')}
请生成结构化的写作指引(JSON格式),包含:
{
"keyPoints": ["核心观点1", "核心观点2", ...],
"dataReferences": ["数据引用1", "数据引用2", ...],
"suggestedStructure": ["段落1主题", "段落2主题", ...],
"focusAreas": ["重点关注领域1", "重点关注领域2", ...]
}
根据研判指令"${seed.focusDirective}",确保分析深入、有数据支撑、有针对性。`;
return await callDeepSeekStructured<WritingGuidance>(prompt);
}
提示词设计要点:
- 明确角色定位:”专业的政策研判Agent”
- 注入SEED参数:
focusDirective决定分析方向 - 结构化输出:强制返回JSON格式,便于后续处理
- 上下文丰富:提供完整的搜索结果和来源信息
3.3 写作Agent:文档生成
export async function writerAgent(
topic: string,
searchResults: SearchResult[],
guidance: WritingGuidance,
seed: GovDocSEED
): Promise<string> {
const prompt = `你是一个专业的公文写作Agent。请根据以下信息撰写一份政府公文:
主题:${topic}
核心观点:
${guidance.keyPoints.map((p, i) => `${i + 1}. ${p}`).join('\n')}
关键数据:
${guidance.dataReferences.map((d, i) => `${i + 1}. ${d}`).join('\n')}
建议结构:
${guidance.suggestedStructure.map((s, i) => `${i + 1}. ${s}`).join('\n')}
重点方向:
${guidance.focusAreas.join('、')}
参考资料:
${searchResults.map((r) => `【${r.source}】${r.snippet}`).join('\n')}
${seed.writingRequirements}`;
return await callDeepSeek(prompt, 0.6, 2000);
}
设计亮点:
writingRequirements直接注入完整的写作要求提示词- 多层信息整合:研判结果 + 原始资料 + 写作规范
- 温度参数0.6:在创造性和稳定性之间平衡
四、评估与诊断系统
4.1 五维评估模型
// lib/evaluators.ts
export async function evaluationAgent(
topic: string,
content: string
): Promise<EvaluationScores> {
const prompt = `你是一个专业的公文评审专家。请对以下公文进行5维度评估,每个维度给出0-1之间的分数,并详细说明打分理由。
主题:${topic}
公文内容:
${content}
评估维度:
1. 政治站位:是否符合政策方针?用词是否准确规范?
2. 事实准确:数据是否有依据?引用是否权威?
3. 逻辑严密:论证是否严谨?段落是否连贯?
4. 公文规范:是否符合公文格式?语言是否得体?
5. 内容深度:是否有深度?建议是否可操作?
返回JSON格式:
{
"政治站位": {
"score": 0.85,
"reason": "用词规范,符合政策导向,但在体现创新发展理念上有所欠缺。"
},
"事实准确": { "score": 0.75, "reason": "..." },
...
}
请客观、严格评分,找出不足之处。`;
return await callDeepSeekStructured<EvaluationScores>(prompt);
}
评估维度选择依据:
- 政治站位:政府公文的首要要求
- 事实准确:信息可靠性
- 逻辑严密:论证质量
- 公文规范:格式规范性
- 内容深度:实用价值
返回示例:
{
"政治站位": { "score": 0.82, "reason": "..." },
"事实准确": { "score": 0.65, "reason": "部分数据缺乏出处" },
"逻辑严密": { "score": 0.78, "reason": "..." },
"公文规范": { "score": 0.90, "reason": "..." },
"内容深度": { "score": 0.58, "reason": "建议缺乏可操作性" }
}
4.2 诊断Agent:问题溯源
找出最弱的两个维度,分析为什么这些维度得分低,以及当前SEED参数的哪些设置导致了问题。
export async function diagnosticAgent(
scores: EvaluationScores,
currentSeed: GovDocSEED
): Promise<DiagnosisResult> {
// 找出最低的两个维度
const sortedScores = Object.entries(scores)
.sort((a, b) => a[1].score - b[1].score)
.slice(0, 2);
const weaknesses = sortedScores.map(([dim, data]) => `${dim}(${data.score})`).join(' 与 ');
const prompt = `你是一个AI系统诊断专家。当前系统生成的公文评分如下:
${Object.entries(scores).map(([k, v]) => `${k}: ${v.score} - ${v.reason}`).join('\n')}
当前SEED参数:
- 搜索深度:${currentSeed.searchDepth}
- 信源范围:${currentSeed.sourceWhitelist.join(', ')}
- 研判指令:${currentSeed.focusDirective}
- 写作要求:${currentSeed.writingRequirements.split('\n')[1]}
识别出的主要弱点:${weaknesses}
请分析:
1. 为什么这些维度得分较低?
2. 当前SEED参数的哪些设置导致了这些问题?
3. 应该如何调整SEED参数来改进?
返回JSON格式:
{
"weakness": "简明描述弱点",
"reason": "深层原因分析(150字内)",
"mutation": [
"搜索深度: 2 -> 15",
"信源范围: 全网 -> 政府官网+统计局+权威智库",
"研判指令: 通用概述 -> 数据驱动+深度问题剖析",
"写作要求: 需要重新生成针对性提示词"
]
}`;
return await callDeepSeekStructured<DiagnosisResult>(prompt);
}
诊断示例输出:
{
"weakness": "事实准确性和内容深度不足",
"reason": "当前搜索深度仅为2,且信源范围过于宽泛,导致检索到的资料权威性不足。研判指令'通用概述'过于泛化,未能引导系统深入挖掘数据和问题。写作要求中缺少对数据引用和来源标注的强制要求。",
"mutation": [
"搜索深度: 2 -> 15(增加信息覆盖度)",
"信源范围: 全网 -> 政府官网+统计局+权威智库+央媒(提升权威性)",
"研判指令: 通用概述 -> 数据驱动+深度问题剖析(明确分析方向)",
"写作要求: 需要AI重新生成,强调数据引用、来源标注、论证深度"
]
}
4.3 架构师Agent:动态提示词生成
这是整个系统最精妙的部分——让AI为AI设计新的提示词。
export async function architectAgent(
diagnosis: DiagnosisResult,
currentSeed: GovDocSEED
): Promise<GovDocSEED> {
const newSeed: GovDocSEED = { ...currentSeed };
// 1. 解析mutation建议,应用到数值参数
diagnosis.mutation.forEach(mutation => {
if (mutation.includes('搜索深度')) {
const match = mutation.match(/(\d+)/g);
if (match && match.length >= 2) {
newSeed.searchDepth = parseInt(match[1]);
}
}
if (mutation.includes('信源')) {
if (mutation.includes('权威') || mutation.includes('政府')) {
newSeed.sourceWhitelist = ['政府官网', '统计局', '权威智库', '央媒'];
}
}
if (mutation.includes('研判')) {
if (mutation.includes('数据') || mutation.includes('深度')) {
newSeed.focusDirective = '数据驱动+深度问题剖析';
}
}
});
// 2. 调用AI动态生成新的writingRequirements
const prompt = `你是一位专业的公文写作指导专家。根据以下问题诊断,生成改进后的"写作要求"提示词。
当前发现的问题:
${diagnosis.weakness}
问题原因分析:
${diagnosis.reason}
改进建议:
${diagnosis.mutation.join('\n')}
请生成一份完整的、针对性的"写作要求"提示词。要求:
1. 针对上述问题进行有针对性的改进
2. 保持格式为标准的写作要求清单
3. 在提示词末尾添加"请直接输出公文内容,不要额外说明。"
4. 不要包含任何markdown代码块或额外的格式符号,直接输出纯文本`;
newSeed.writingRequirements = await callDeepSeek(
[
{ role: 'system', content: '你是一位经验丰富的公文写作提示词设计专家,能够根据问题诊断生成精准有效的写作要求。' },
{ role: 'user', content: prompt }
],
0.6,
1500
);
return newSeed;
}
AI生成的新提示词示例:
写作要求:
1. 文风温度:客观严谨,数据驱动
2. 必须引用具体数据,并在引用处标注来源(如:根据XX统计局2024年数据...)
3. 加强问题分析的深度,明确阐述因果关系,避免跳跃式推理
4. 提出的建议需具体可操作,包含实施主体、时间节点、预期效果
5. 论证逻辑:现状分析(数据支撑)→ 问题识别 → 原因剖析 → 解决方案
6. 字数控制在1000-1500字
7. 确保每个论点都有事实或数据支撑
请直接输出公文内容,不要额外说明。
关键创新点:
- 不是硬编码的模板,而是基于诊断结果动态生成
- AI理解了”写作要求”的本质,能够设计出针对性的指令
- 实现了”AI为AI编程”的元认知能力
五、流式输出与实时反馈
为了让用户感知系统的运行过程,我们使用Server-Sent Events实现流式输出。
5.1 后端流式API
// app/api/generate/route.ts
function createStreamResponse() {
const encoder = new TextEncoder();
const stream = new TransformStream();
const writer = stream.writable.getWriter();
const sendLog = async (msg: string, type: 'info' | 'success' | 'warning' | 'error' = 'info') => {
await writer.write(encoder.encode(`data: ${JSON.stringify({
type: 'log',
data: { time: new Date().toLocaleTimeString(), msg, type }
})}\n\n`));
};
const sendStatus = async (status: string) => {
await writer.write(encoder.encode(`data: ${JSON.stringify({
type: 'status',
data: status
})}\n\n`));
};
const sendScores = async (scores: EvaluationScores, version: string) => {
await writer.write(encoder.encode(`data: ${JSON.stringify({
type: 'scores',
data: { scores, version }
})}\n\n`));
};
// ... 其他发送函数
return { stream: stream.readable, sendLog, sendStatus, sendScores, /* ... */ };
}
export async function POST(request: NextRequest) {
const { topic } = await request.json();
const { stream, sendLog, sendStatus, sendContent, sendScores, sendSeed, sendDiagnosis, sendSearchResults, close } = createStreamResponse();
(async () => {
// V1阶段
await sendStatus('running_v1');
await sendLog('System Init: Topic="${topic}"');
const searchResults = await searchAgent(topic, v1Seed);
await sendLog(`Agent [Search] returned ${searchResults.length} results`);
await sendSearchResults(searchResults, 'v1');
const guidance = await insightAgent(topic, searchResults, v1Seed);
await sendLog('Agent [Insight] generated guidance');
const v1Content = await writerAgent(topic, searchResults, guidance, v1Seed);
await sendContent(v1Content, 'v1');
// 评估阶段
await sendStatus('evaluating_v1');
const v1Scores = await evaluationAgent(topic, v1Content);
await sendScores(v1Scores, 'v1');
// 进化阶段
await sendStatus('evolving');
const diagnosis = await diagnosticAgent(v1Scores, v1Seed);
await sendDiagnosis(diagnosis);
const v2Seed = await architectAgent(diagnosis, v1Seed);
await sendSeed(v2Seed, 'v2');
// V2阶段
await sendStatus('running_v2');
// ... V2执行流程
await sendStatus('done');
await close();
})();
return new Response(stream, {
headers: {
'Content-Type': 'text/event-stream',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
},
});
}
5.2 前端实时接收
// app/page.tsx
const startSimulation = async () => {
const response = await fetch('/api/generate', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({ topic })
});
const reader = response.body?.getReader();
const decoder = new TextDecoder();
let buffer = '';
let currentPhase: 'v1' | 'v2' = 'v1';
while (true) {
const { done, value } = await reader.read();
if (done) break;
buffer += decoder.decode(value, { stream: true });
const lines = buffer.split('\n\n');
buffer = lines.pop() || '';
for (const line of lines) {
if (!line.startsWith('data: ')) continue;
const event = JSON.parse(line.replace('data: ', ''));
switch (event.type) {
case 'status':
setStatus(event.data);
if (event.data === 'running_v2') currentPhase = 'v2';
break;
case 'log':
if (currentPhase === 'v1') {
setV1Logs(prev => [...prev, event.data]);
} else {
setV2Logs(prev => [...prev, event.data]);
}
break;
case 'content':
if (event.data.version === 'v1') {
setV1Content(event.data.content);
} else {
setV2Content(event.data.content);
}
break;
case 'scores':
if (event.data.version === 'v1') {
setV1Scores(event.data.scores);
} else {
setV2Scores(event.data.scores);
}
break;
case 'diagnosis':
setDiagnosis(event.data);
break;
case 'searchResults':
if (event.data.version === 'v1') {
setV1SearchResults(event.data.results);
} else {
setV2SearchResults(event.data.results);
}
break;
}
}
}
};
六、UI设计:可视化进化过程
6.1 三列布局
┌─────────────┬─────────────┬─────────────┐
│ V1 Loop │ Engine │ V2 Loop │
│ │ │ │
│ ┌─────────┐ │ ┌─────────┐ │ ┌─────────┐ │
│ │ SEED │ │ │ Status │ │ │ SEED │ │
│ └─────────┘ │ └─────────┘ │ └─────────┘ │
│ │ │ │
│ ┌─────────┐ │ ┌─────────┐ │ ┌─────────┐ │
│ │ Search │ │ │Diagnosis│ │ │ Search │ │
│ │ Results │ │ │ │ │ │ Results │ │
│ └─────────┘ │ └─────────┘ │ └─────────┘ │
│ │ │ │
│ ┌─────────┐ │ ┌─────────┐ │ ┌─────────┐ │
│ │Terminal │ │ │Mutation │ │ │Terminal │ │
│ └─────────┘ │ └─────────┘ │ └─────────┘ │
│ │ │ │
│ ┌─────────┐ │ │ ┌─────────┐ │
│ │Document │ │ │ │Document │ │
│ └─────────┘ │ │ └─────────┘ │
│ │ │ │
│ ┌─────────┐ │ │ ┌─────────┐ │
│ │ Radar │ │ │ │ Radar │ │
│ │ Chart │ │ │ │ Chart │ │
│ └─────────┘ │ │ └─────────┘ │
└─────────────┴─────────────┴─────────────┘
Mutation是指变体,根据诊断输出新的SEED. Radar Chart是指五维雷达图.
6.2 五维雷达图对比
使用SVG绘制五维雷达图,直观对比V1和V2的评分变化:
const RadarChart = ({ v1Scores, v2Scores, showComparison }: Props) => {
const size = 280;
const center = size / 2;
const radius = 90;
const keys = Object.keys(v1Scores);
const total = keys.length;
const angleSlice = (Math.PI * 2) / total;
const getCoordinates = (value: number, index: number) => {
const angle = index * angleSlice - Math.PI / 2;
return {
x: center + radius * value * Math.cos(angle),
y: center + radius * value * Math.sin(angle)
};
};
// 绘制网格线
const gridLevels = [0.2, 0.4, 0.6, 0.8, 1.0];
return (
<svg width={size} height={size}>
{/* 绘制同心多边形网格 */}
{gridLevels.map((level, idx) => (
<polygon
key={idx}
points={keys.map((_, i) => {
const { x, y } = getCoordinates(level, i);
return `${x},${y}`;
}).join(' ')}
fill="none"
stroke="#e5e7eb"
strokeWidth="1"
/>
))}
{/* V1数据多边形 */}
<polygon
points={keys.map((key, i) => {
const { x, y } = getCoordinates(v1Scores[key].score, i);
return `${x},${y}`;
}).join(' ')}
fill="rgba(59, 130, 246, 0.2)"
stroke="#3b82f6"
strokeWidth="2"
/>
{/* V2数据多边形(对比模式) */}
{showComparison && v2Scores && (
<polygon
points={keys.map((key, i) => {
const { x, y } = getCoordinates(v2Scores[key].score, i);
return `${x},${y}`;
}).join(' ')}
fill="rgba(249, 115, 22, 0.25)"
stroke="#f97316"
strokeWidth="2"
/>
)}
{/* 维度标签 */}
{keys.map((key, i) => {
const { x, y } = getCoordinates(1.25, i);
return (
<text key={i} x={x} y={y} textAnchor="middle" className="text-[10px] fill-gray-500">
{key}
</text>
);
})}
</svg>
);
};
6.3 Terminal日志组件
模拟终端风格,实时显示Agent执行日志:
const AgentLog = ({ logs, title }: { logs: LogItem[]; title: string }) => {
const scrollRef = useRef<HTMLDivElement>(null);
useEffect(() => {
if (scrollRef.current) {
scrollRef.current.scrollTop = scrollRef.current.scrollHeight;
}
}, [logs]);
return (
<div className="bg-[#1e1e1e] rounded-xl overflow-hidden border border-gray-700">
<div className="bg-[#2d2d2d] px-4 py-2 flex items-center gap-2">
<div className="w-3 h-3 rounded-full bg-[#ff5f56]"></div>
<div className="w-3 h-3 rounded-full bg-[#ffbd2e]"></div>
<div className="w-3 h-3 rounded-full bg-[#27c93f]"></div>
<span className="ml-auto text-gray-500 text-xs">{title}</span>
</div>
<div ref={scrollRef} className="p-4 h-56 overflow-y-auto font-mono text-xs">
{logs.map((log, idx) => (
<div key={idx} className="flex gap-3">
<span className="text-gray-500">[{log.time}]</span>
<span className={
log.type === 'error' ? 'text-red-400' :
log.type === 'success' ? 'text-emerald-400' :
log.type === 'warning' ? 'text-yellow-400' :
'text-blue-300'
}>
{log.msg}
</span>
</div>
))}
</div>
</div>
);
};
实时日志示例:
[14:23:01] System Init: Topic="天津市人工智能现状"
[14:23:01] Agent [Search] executing... depth=2
[14:23:03] Agent [Search] returned 2 results
[14:23:03] Agent [Insight] directive: "通用概述"
[14:23:08] Agent [Insight] generated guidance
[14:23:08] Agent [Writer] drafting content...
[14:23:15] V1 Document Generated.
[14:23:15] Triggering 5D Evaluation Model...
[14:23:22] Evaluation completed.
[14:23:22] Analyzing V1 performance...
[14:23:25] Diagnostician identified weaknesses
[14:23:25] Architect generating new SEED...
[14:23:30] SEED v2.0 (Evolved) generated
[14:23:30] Loading SEED v2.0 (Evolved)...
[14:23:30] Agent [Search] deep scan mode... sources=政府官网,统计局,权威智库,央媒
[14:23:35] Agent [Search] retrieved 15 high-value datasets
...
七、技术栈与依赖
{
"dependencies": {
"next": "^16.0.8",
"react": "^19.0.0",
"typescript": "^5",
"@tavily/core": "^1.x",
"lucide-react": "^0.x"
}
}
环境变量配置
# .env.local
DEEPSEEK_API_KEY=sk-xxxxxxxxxxxxx
TAVILY_API_KEY=tvly-xxxxxxxxxxxxx
八、核心代码目录结构
govdoc-system/
├── app/
│ ├── api/
│ │ └── generate/
│ │ └── route.ts # 流式API端点
│ ├── page.tsx # 主页面UI
│ └── layout.tsx # 布局
├── lib/
│ ├── agents.ts # 搜索、研判、写作Agent
│ ├── evaluators.ts # 评估、诊断、架构师Agent
│ ├── deepseek.ts # DeepSeek API封装
│ └── types.ts # TypeScript类型定义
└── .env.local # 环境变量
九、实验效果分析
9.1 典型进化案例
主题:天津市人工智能现状
V1表现(基线SEED):
评分结果:
- 政治站位:0.82
- 事实准确:0.65 ← 弱点
- 逻辑严密:0.78
- 公文规范:0.90
- 内容深度:0.58 ← 弱点
诊断结果:
- 弱点:事实准确性和内容深度不足
- 原因:搜索深度仅为2,信源范围过于宽泛,研判指令泛化
- 突变策略:
1. 搜索深度 2 → 15
2. 信源范围:全网 → 政府+统计+智库+央媒
3. 研判指令:通用概述 → 数据驱动+深度剖析
4. 写作要求:AI重新生成针对性提示词
V2表现(进化SEED):
评分结果:
- 政治站位:0.88 (+0.06)
- 事实准确:0.89 (+0.24) ← 显著提升
- 逻辑严密:0.85 (+0.07)
- 公文规范:0.92 (+0.02)
- 内容深度:0.83 (+0.25) ← 显著提升
改进效果:
- 引用了15个权威数据源
- 标注了具体来源(如"根据天津市统计局2024年Q1数据")
- 分析深度提升,包含了产业链分析和政策建议
- 提出了5条具体可操作的建议,包含实施主体和时间节点
9.2 进化机制的有效性
通过10个不同主题的测试,统计结果如下:
| 维度 | V1平均分 | V2平均分 | 提升幅度 |
|---|---|---|---|
| 政治站位 | 0.81 | 0.87 | +7.4% |
| 事实准确 | 0.68 | 0.86 | +26.5% |
| 逻辑严密 | 0.75 | 0.84 | +12.0% |
| 公文规范 | 0.88 | 0.91 | +3.4% |
| 内容深度 | 0.62 | 0.82 | +32.3% |
关键发现:
- 事实准确和内容深度提升最显著(25%+),说明进化机制有效针对弱点改进
- 公文规范提升较小,因为V1已经较好(基线提示词已经强调格式)
- 诊断Agent准确识别了SEED参数与输出质量的因果关系
十、技术亮点与创新
10.1 元学习能力
传统方法:硬编码参数调整规则
if score < 0.7:
seed.searchDepth += 5
本系统:AI理解”为什么”并自主决策
- 诊断Agent分析深层原因
- 架构师Agent设计新的提示词
- 实现了”AI为AI编程”的元认知
10.2 动态提示词工程
静态模板:
写作要求:${temperature}温度,${length}字数,${format}格式
动态生成:
// AI根据诊断结果,完整重写提示词
newSeed.writingRequirements = await callDeepSeek(`
根据以下问题诊断,生成改进后的写作要求:
问题:${diagnosis.weakness}
原因:${diagnosis.reason}
建议:${diagnosis.mutation}
...
`);
10.3 多模态观测能力
- Terminal日志:过程透明
- 雷达图:效果可视化
- 搜索结果展示:信息溯源
- 诊断报告:原因分析
10.4 真实RAG集成
- 使用Tavily进行真实网页搜索
- 信源过滤(政府官网、统计局优先)
- 搜索结果可点击溯源
十一、局限与改进方向
11.1 当前局限
- 单次进化:目前只有V1→V2,未实现多代进化
- 评估主观性:5维评估依赖AI判断,缺少人类反馈
- SEED空间有限:当前只有4个参数,可扩展性受限
- 计算成本:每次生成需要多次API调用(约15-20次)
11.2 改进方向
1. 多代进化与收敛检测
while (!converged && generation < MAX_GENERATIONS) {
const newDoc = await generateWithSeed(currentSeed);
const scores = await evaluate(newDoc);
if (scores.average > 0.90) {
converged = true; // 收敛条件
}
currentSeed = await evolve(scores, currentSeed);
generation++;
}
2. 人类反馈强化学习
- 收集用户对V2文档的满意度评分
- 建立”成功SEED”知识库
3. 扩展SEED参数空间
interface ExtendedSEED {
// 当前参数
searchDepth: number;
sourceWhitelist: string[];
focusDirective: string;
writingRequirements: string;
// 新增参数
thinkingChain: boolean; // 是否启用思维链
multiModelEnsemble: string[]; // 多模型集成
exampleDocuments: string[]; // Few-shot示例
constraintRules: Rule[]; // 硬约束规则
creativityBudget: number; // 创造性预算
}
4. A/B测试与SEED优化
- 并行生成多个SEED变体
- 对比评估选择最优
- 使用遗传算法优化SEED参数
5. 领域迁移
- 当前针对政府公文,可迁移到:
- 学术论文写作
- 技术文档生成
- 商业报告撰写
- 代码文档自动化
十二、总结
本文详细介绍了一个自我改善的AI Agent系统的完整设计与实现。核心创新点包括:
- 双循环架构:Inner Loop执行 + Outer Loop反思
- SEED进化机制:可变参数作为”基因”,通过评估→诊断→突变实现自我改进
- 动态提示词生成:让AI为AI设计提示词,实现元学习能力
- 多Agent协作:6个专业Agent各司其职,形成完整的工作流
- 流式可视化:实时展示进化过程,提升可解释性
这套架构不仅适用于公文写作,更是一种通用的AI自我优化范式。随着大模型能力的提升,我们可以构建越来越”聪明”的系统——它们不仅能执行任务,还能反思、学习和进化。
附录:完整源码
完整项目代码:已经放在星球中了.
关键文件:
lib/agents.ts- 搜索、研判、写作Agent实现lib/evaluators.ts- 评估、诊断、架构师Agent实现app/api/generate/route.ts- 流式API端点app/page.tsx- 前端UI实现
运行方式:
# 1. 安装依赖
npm install
# 2. 配置环境变量
cp .env.example .env.local
# 编辑 .env.local,填入 DEEPSEEK_API_KEY 和 TAVILY_API_KEY
# 3. 运行开发服务器
npm run dev
# 4. 访问 http://localhost:3000
联系作者
让AI的技术被商业赋能, 商业将AI的价值放大.
星球中有开箱即用的源码、讲解视频、提示词,以及落地经验.
欢迎加入我们,思考技术对商业的价值.

如果你有场景和困难, 欢迎找我聊聊AI
- 可以找AI咨询
- 可以找我AI落地
我的微信: leigeaicom


{kind=link}
大家一起来讨论