
Table of Contents
传统 RAG 让你的法律条款”支离破碎”?98.7% 准确率的新方案来了!
注意: 这是长文档问答的最佳方案.
一、痛点:传统 RAG 为什么会”语义中断”?
如果你正在做企业级知识库、法律文档检索或医疗病历分析,一定遇到过这样的问题:
场景还原:
假设你有一份《贷款合同》,其中有这样的条款:
第三条 贷款条件
借款人需满足以下条件:
1. 年龄在 18-65 周岁之间
2. 具有稳定的收入来源
3. 个人征信记录良好
第四条 违约责任
如借款人违反第三条任一规定,贷款方有权...
用户提问:”征信不良会有什么后果?”
传统 RAG 系统的处理流程:
- 文档按固定长度(如 512 Token)切块
- 第三条的后半部分 + 第四条的前半部分被切成一块
- 检索时只召回了”第四条”的片段
- 结果:AI 回答不完整,因为”第三条”的上下文丢失了!
这就是典型的 “语义中断” 问题——切块时破坏了逻辑完整性。
二、为什么传统 Chunking 不适合长文档?
2.1 传统方法的三大缺陷
| 问题 | 影响 | 典型场景 |
|---|---|---|
| 固定长度切块 | 无视语义边界,强行切断 | 法律条款、技术手册 |
| 上下文割裂 | 前因后果分离,检索不准 | 医疗病历、审计报告 |
| 重复信息冗余 | 为了保证连续性,滑动窗口导致存储浪费 | 几十万字的文档 |
2.2 哪些场景必须抛弃传统方法?
强烈推荐使用新方案:
- ✅ 征信报告(条款之间有强依赖关系)
- ✅ 法律尽调文件(需要完整的逻辑链)
- ✅ 医疗病历(诊断结论依赖检查记录)
- ✅ 技术手册(操作步骤不能拆分)
不推荐:
- ❌ QA 问答对(本身就是独立的碎片)
- ❌ 新闻资讯(每篇文章独立)
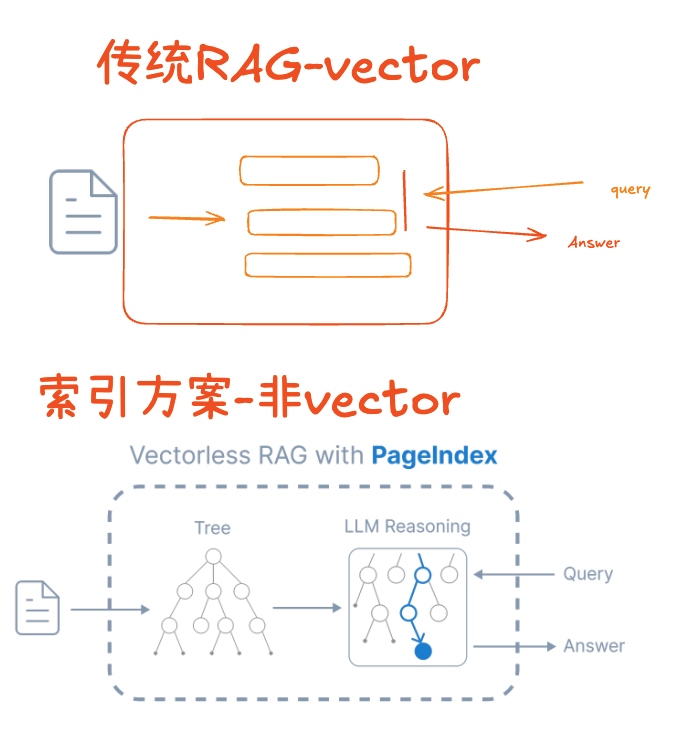
三、技术原理:PageIndex 如何从”碎纸机”变成”结构树”?
3.1 核心思想
传统 RAG:
文档 → 切碎成小块 → 向量化 → 检索
(信息丢失)
PageIndex 方案:
文档 → 保留页面结构 → 智能索引 → 精准定位
(语义完整)
3.2 性能对比
官方测试数据准确度: 98.7%
核心优势: 在保持页面语义完整性的同时,通过结构化索引大幅提升召回率。
3.3 工作流程示意
构建索引而非切分为小的碎片.
四、实战改造:让 DeepSeek 替代 OpenAI
4.1 为什么选择 DeepSeek?
对于中文长文档场景,DeepSeek 性价比高达 100 倍!而且对国内使用友好.
4.2 原版代码的缺陷
原始 PageIndex 项目硬编码了 OpenAI SDK:
# 问题 1: 无法切换 API 地址
async with openai.AsyncOpenAI(api_key=api_key) as client:
response = await client.chat.completions.create(...)
# 问题 2: API Key 写死在配置中
api_key = CHATGPT_API_KEY # 无法灵活切换
4.3 改造方案(完整代码)
修改位置 1: ChatGPT_API_async 函数(第 93-130 行)
改造前:
async def ChatGPT_API_async(model, prompt, api_key=CHATGPT_API_KEY):
max_retries = 10
messages = [{"role": "user", "content": prompt}]
for i in range(max_retries):
try:
async with openai.AsyncOpenAI(api_key=api_key) as client:
response = await client.chat.completions.create(
model=model,
messages=messages,
temperature=0,
)
return response.choices[0].message.content
except Exception as e:
print('************* Retrying *************')
logging.error(f"Error: {e}")
if i < max_retries - 1:
await asyncio.sleep(1)
else:
logging.error('Max retries reached for prompt: ' + prompt)
return "Error"
改造后(支持 DeepSeek):
async def ChatGPT_API_async(model, prompt, api_key=CHATGPT_API_KEY):
max_retries = 10
messages = [{"role": "user", "content": prompt}]
# ✨ 核心改动:根据模型名称自动切换 API 地址
base_url = None
if model and 'deepseek' in model.lower():
base_url = "https://api.deepseek.com"
# 优先使用 DeepSeek 专用 API Key
if api_key is None or api_key == CHATGPT_API_KEY:
api_key = os.getenv("DEEPSEEK_API_KEY", CHATGPT_API_KEY)
for i in range(max_retries):
try:
# ✨ 灵活切换客户端
if base_url:
async with openai.AsyncOpenAI(api_key=api_key, base_url=base_url) as client:
response = await client.chat.completions.create(
model=model,
messages=messages,
temperature=0,
)
return response.choices[0].message.content
else:
async with openai.AsyncOpenAI(api_key=api_key) as client:
response = await client.chat.completions.create(
model=model,
messages=messages,
temperature=0,
)
return response.choices[0].message.content
except Exception as e:
print('************* Retrying *************')
logging.error(f"Error: {e}")
if i < max_retries - 1:
await asyncio.sleep(1)
else:
logging.error('Max retries reached for prompt: ' + prompt)
return "Error"
改造要点:
- 自动识别模型:检测模型名称中是否包含 “deepseek”
- 动态 base_url:DeepSeek 模型使用
https://api.deepseek.com - API Key 优先级:环境变量
DEEPSEEK_API_KEY> 默认配置
4.4 配置环境变量
在项目根目录创建 .env 文件:
# DeepSeek API 配置
DEEPSEEK_API_KEY=your_deepseek_api_key_here
# 如果仍需使用 OpenAI(可选)
CHATGPT_API_KEY=your_openai_api_key_here
4.5 使用示例
# 使用 DeepSeek 模型
result = await ChatGPT_API_async(
model="deepseek-chat", # 自动识别并切换到 DeepSeek API
prompt="总结这份合同的核心条款"
)
# 使用 OpenAI 模型(兼容原有代码)
result = await ChatGPT_API_async(
model="gpt-4",
prompt="总结这份合同的核心条款"
)
五、实际效果对比
5.1 测试案例:某公司投资协议(20 页)
提问:”如果公司估值低于 5000 万,投资人有什么权利?”
| 方案 | 召回内容 | 答案质量 |
|---|---|---|
| 传统 RAG | 只检索到第 12 页的”估值调整条款” | ⚠️ 不完整(缺少第 8 页的”前置条件”) |
| PageIndex | 完整返回第 8-12 页的逻辑链 | ✅ 准确(包含触发条件 + 执行细节) |
六、注意事项与优化建议
6.1 何时不适合用 PageIndex?
- ❌ 文档小于 5 页(直接全文检索更快)
- ❌ 内容高度碎片化(如微博、短消息)
- ❌ 实时数据流(需要流式处理)
七、总结
关键收获:
- 长文档检索必须考虑语义完整性,而非单纯追求向量相似度
- DeepSeek 在中文场景下性价比远超 OpenAI
- 开源项目改造时,动态切换 API 是最小侵入的方式
源码: 加入星球可获取源码.
在我的知识星球,我们不谈虚的
我希望能找到AI与应用上的融合: AI的技术被商业赋能, 商业将AI的价值放大.
这里有企业家、创业者、独立开发者、AI极客, 我们有微信群, 可以一起交流. 希望可以给大家创造更大的机会.
我一直在一线做AI落地. 我希望这些经验可以帮到你.
欢迎加入我们,思考技术对商业的价值.

如果你有场景和困难, 欢迎找我聊聊AI
- 可以找AI咨询
- 可以找我AI落地
我的微信: leigeaicom


{kind=link}
大家一起来讨论